A Survey on In-context Learning
In-context Learning(上下文表征学习)
ICL本身
ICL在LLMs时代非常有用,可以用来评判大语言模型。
简单来说,ICL允许在大模型当中应用一些简单的例子来进行上下文学习,即可以从上下文当中的几个示例来学习,其中,在数学推理(主要应用了CoT)等问题上的能力已经得到了验证。
具体来说,ICL的作用就是给出一些示例,直接丢给大模型,让他去根据其中的潜在模式来给出回答和预测(个人理解是类似few-shot的问答),如下图所示。
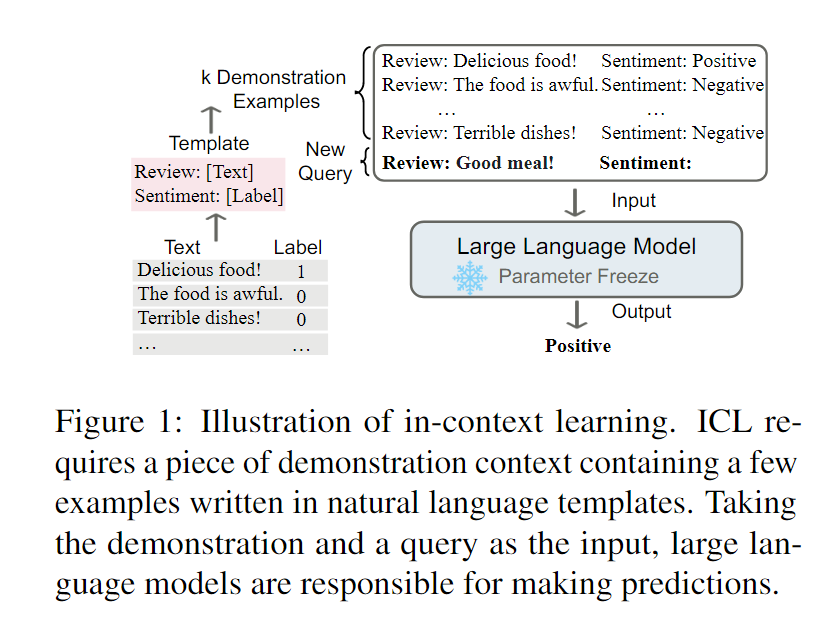
给出ICL的具体定义:ICL是一种范式,这种范式允许语言模型仅仅在被以演示的方法给出少量样本后就可以学习任务。(Incontext learning is a paradigm that allows language models to learn tasks given only a few examplesin the form of demonstration).
ICL的优点:
- 使用可解释的方法来和LLM交互,可以通过改变prompt的构造方法和知识本身来简单的把相关知识融入
- 可解释性强,类似人类学习类比的决策过程
- 无需训练,减少了计算成本
ICL和大模型相关
比较显著的特性包括,选择的上下文示例的内容,prompt模板乃至上下文示例的顺序都对ICL的性能有影响,此外,尽管普通的GPT-3也可以表现出ICL能力,但是在预训练期间的适应可以显著提升表现能力。

ICL和prompt learning & few-shot learning
综述提到了ICL与这两者的关系。严格来说,ICL算是prompt learning的一个子类;而相较于few-shot learning来说,ICL不用参数更新,而是直接使用预训练的LLMs。
ICL在LLMs当中的各个过程
简单按照前文给出的图来看一下LLMs的各个过程当中ICL发挥的作用,主要分为Training和Inference两个阶段。
Training
Model Warmup
模型预热(model warmup)本身的含义是在预训练的LLMs后,多做一些简单的继续训练(continual training)。
这里提两点:
- warmup阶段会修改或者添加LLM的参数
- 与finetune不同,warmup本身是为了提升ICL能力,而不特异于任务(但是原文后文当中还是混淆了warmup和finetune两个词^^)
有监督的In-context训练
- MetaICL: Learning to Learn In Context
在大量任务上调整预训练的语言模型,从而提升ICL能力。具体的做法是针对每种不同的任务选取了k+1个实例,从前k个实例当中学习新任务,在最后一个实例上回答问题,计算交叉熵损失。
比较逆天的地方在于,本文在不同的任务集上进行了实验,包括142个不同种类的数据集以及7个不同的实验设置,总共有52个独特的任务。
在我看来,他这里的元训练(meta-trained)的过程和ICL的流程是类似的,本质上也是为了后续LM能够更好地被使用在ICL当中,所以这里进行meta-trained的过程当中也是类似ICL将各种输入数据拼接在一起的构造方法。
对于构造的QA问题对(k个实例(x,y)和最后一个$x_{k+1}$),还给出了候选项$c_i\in{C}$,对分类问题来说是标签,对问答问题来说是候选项,每组问题返回最大条件概率的标签。
同时,文中还给出了Channel MeatICL的训练方法,本质上是给出k个实例(y,x)和最后一个输出$y_{t+1}$,来反向预测$x_{t+1}$
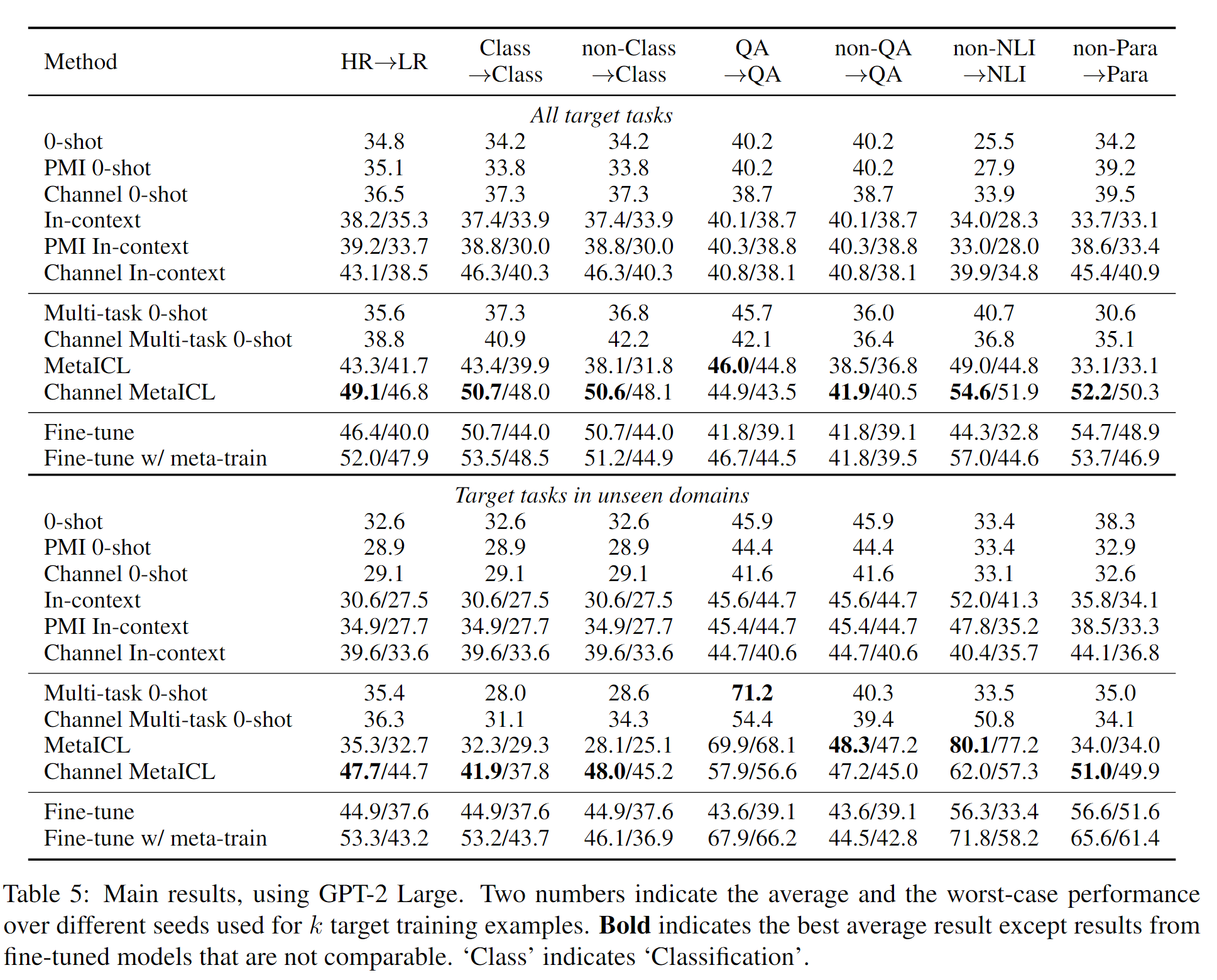
具体的实验设置和数据集跨度很大,这里仅仅放上最终结果图。
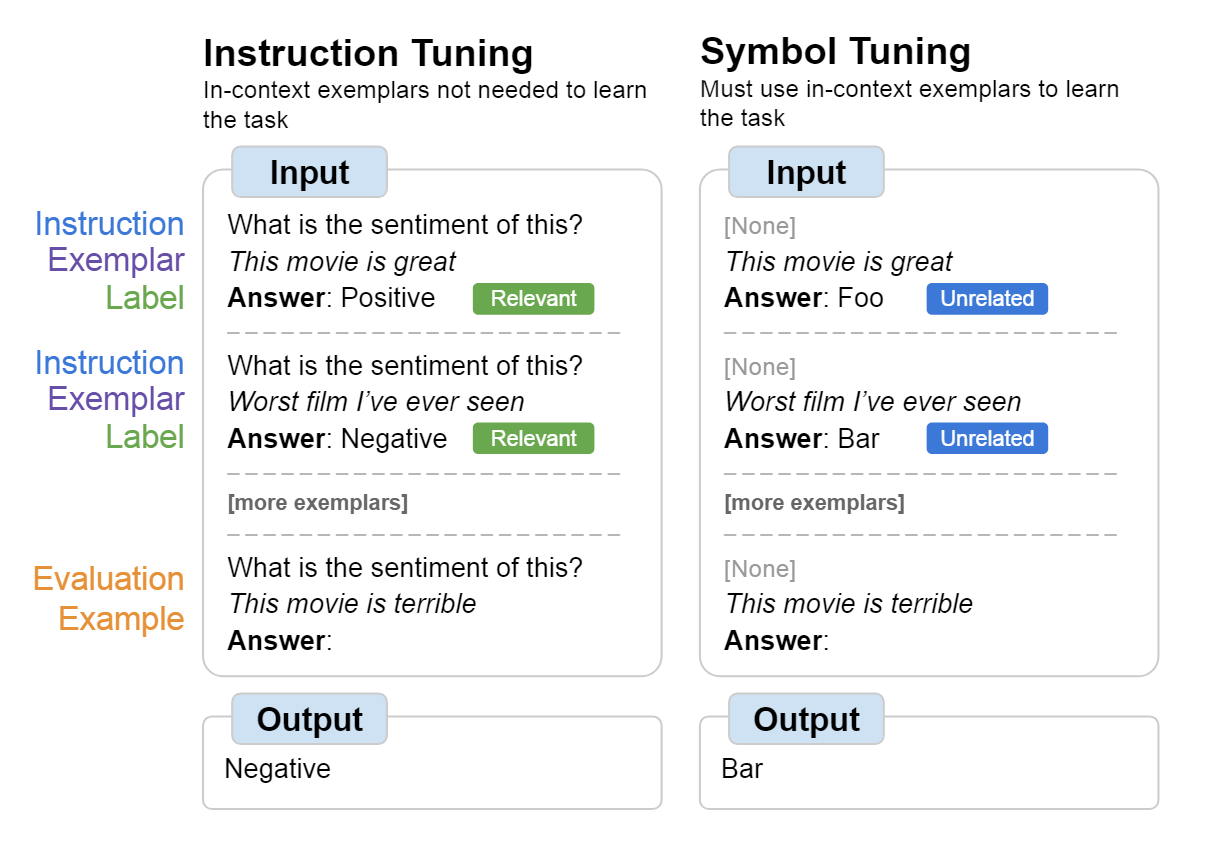
- Symbol tuning improves in-context learning in language models
提出了符号调整,我们知道ICL当中的输入输出往往需要通过一些特殊符号分隔,包括特有的标签往往也具有特定含义(例如分类任务当中的negative和positive标签)。因此这里尝试将特殊的标签替换为没有实际意义的标签,例如前面提到的negative和positive替换为foo和bar,这样可以保证模型在不能利用到自然语言找出任务的时候,就必须去学习输入到标签的映射关系。
- Finetuned Language Models are Zero-Shot Learners Pre-Training to Learn in Context 提出了指令微调的方法,但是感觉非常玄幻,貌似仅仅通过调整任务的描述这样的指令,来提升模型在特定任务上的表现效果。
核心的思路在于,预训练的时候在多种不同的任务类型上进行指令微调,而在推理过程中即使是没见过的任务类型也能取得很好的效果。这样的训练方法可以提升模型遵守给出的指令的能力,因此即使是对于看不到的指令也能够很好的解决问题。
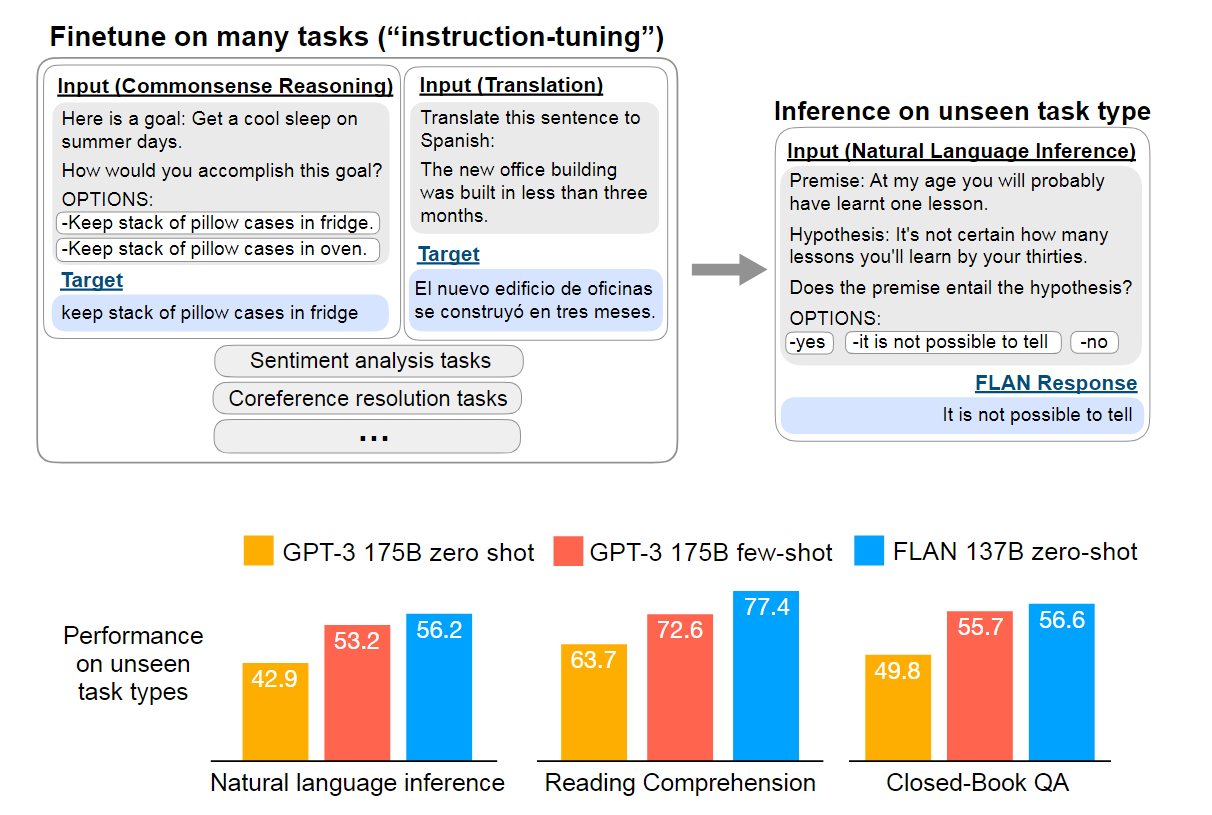
值得一提的是,我个人认为这里取得效果的强弱与任务的种类和构造模板的数量密不可分,原文针对多种不同的任务构造了很多不同的模板,而且这里又一次用到了反向问答的技巧。例如针对情感分类任务,要求其直接根据情感产生电影评论。
自监督的In-context训练
- Improving In-Context Few-Shot Learning via Self-Supervised Training
出发点:假设了改进ICL学习的一种方法是提升模型对于特定格式的理解能力。
另外写了一篇简单的博客,主要是采用了四种不同的预训练任务,自动的生成训练数据并且进行自监督的训练。针对不同的训练任务,都采用了不同的数据生成方法。四种方法包括下一句预测,短语预测,掩码词语预测以及分类任务。
- Pre-Training to Learn in Context
和上一篇文章类似,同样是着眼于预训练任务当中缺少了关于ICL相关内容的训练,因此提出了PICL,相较于上篇工作,本工作在更大规模的数据集上进行了NLP任务的实践,证明了其泛化性更强。
本文同样是针对文本内容进行训练数据的自我构造,提出了一个有趣的观察,许多文本文档当中都包含了很多“内在任务”,LMs对每个段落进行语言建模的过程中,也都隐含的同时执行了相应的内在任务。
针对不同的内在任务,在原文的语料当中寻找相似的任务,并且将相似的任务拼接起来作为meta-train的实例,如下图所示:
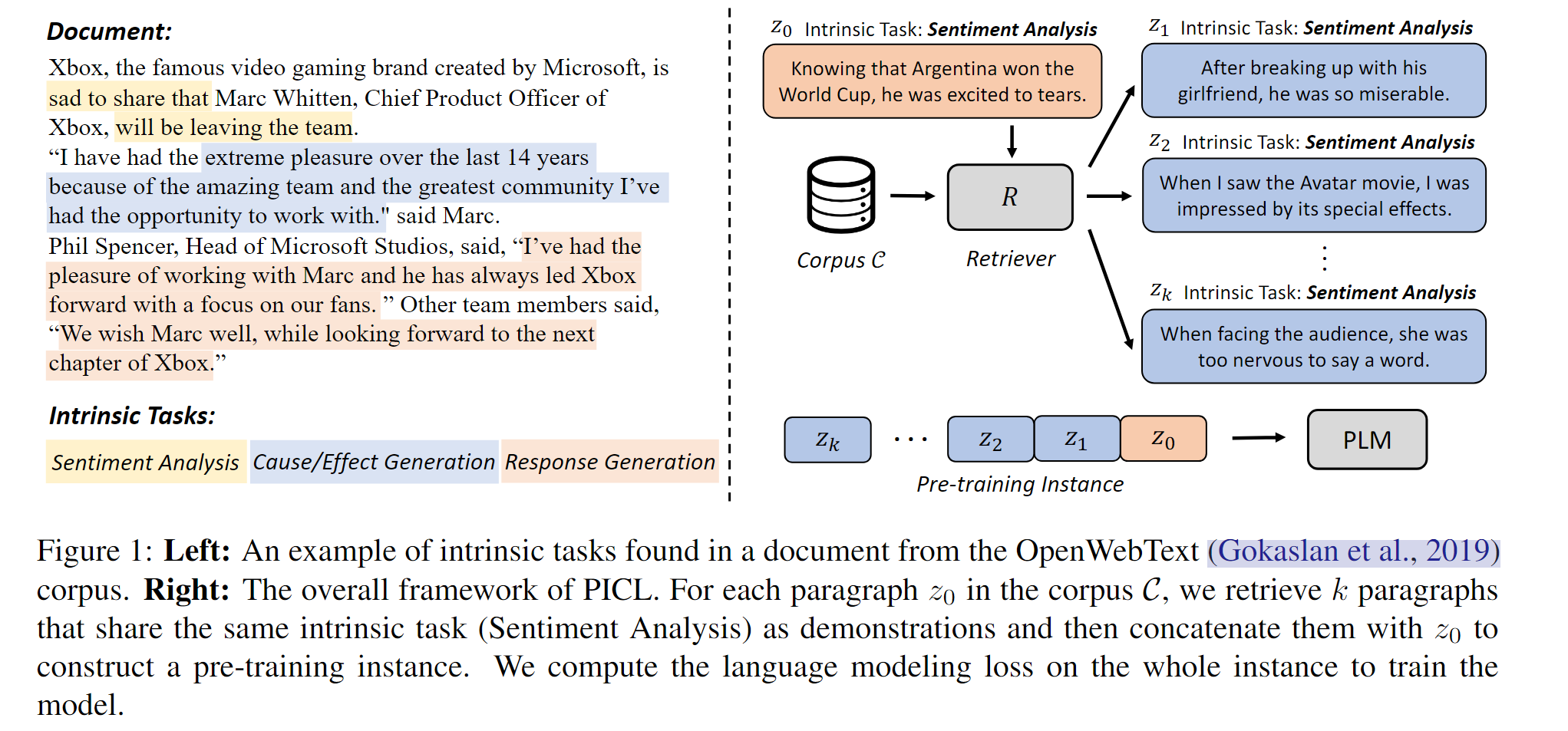
和上篇工作太过相似了,唯一值得强调的一点,这里的语料泛化性更强,是一个大规模的通用语料库。
此外,这里利用对比学习的方法来寻来你了一个任务语义编码器,来构造各种不同的内在任务集合。将相同内在任务的两个段落视为正对,将不同的任务段落视为负对,进行对比学习。
Inference
Demonstration Designing
前面提到的内容是训练部分的提升,然而对于chatGPT这样的模型,其并不开源训练端口,在这样的模型上进行ICL学习是不能使用微调参数的做法的。
然而好在许多研究都表明了,ICL的性能依赖于演示(demonstration)本身,包括演示的格式以及演示的示例顺序等等,因此后文的内容会从演示组织(demonstration organization)以及演示格式(demonstration formatting)上两个方面进行介绍。
Demonstration Organization
所谓演示组织,其实更侧重于如何选择示例以及选择示例的顺序。
Demonstration Selection
无监督方法
- What Makes Good In-Context Examples for GPT-3?
其方法比较符合直觉,直接选用语义上和测试样本最相似的示例来制定相关的上下文样本,原文当中特别提到了,针对“表格-文本生成”以及“开放域问答”这两个任务取得了更加显著的收益。
具体来说,选用相似的句子采用了BERT,RoBERTa或者XLNet这类语义模型/在特定任务和数据集上微调的句子编码器,根据CLS标签将句子分隔开来,同时使用简单的KNN网络来选取前k个相似的句子作为示例。
感觉操作起来比较简单,所使用的方法也比较符合直觉。
- An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
其方法也符合直觉,但是略微有些复杂,贴一张图来简单解释一下。
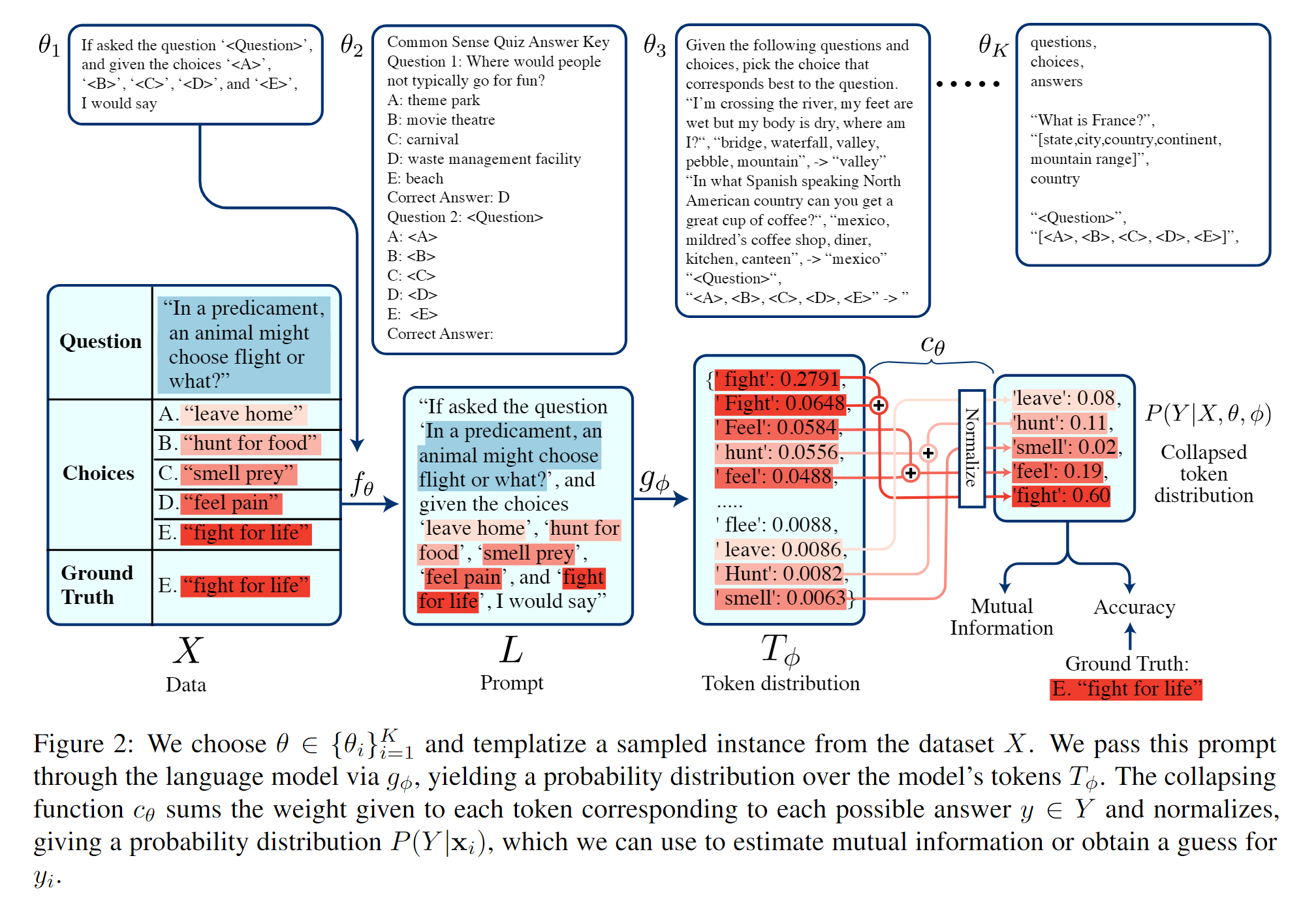
- 在训练数据上,针对每个不同的prompt模板,直接扔进语言模型,让其给出对于不同回答的概率分布(这里的概率分布包括首字母大小写的两种情况),根据大小写的概率分布加权求和,给出正确答案。
- 在prompt木板上,针对每个不同的模板后,可以根据产生的输出和对应的模板的互信息来判断,相关性越强的是更好的模板。
- Demystifying Prompts in Language Models via Perplexity Estimation
主要的思路题目上都说了,选择prompt当中的示例数据的过程中使用困惑度作为判断指标,主要的motivation来源于,提示的性能与模型熟悉它包含的语言是相关的。
本文主要的操作流程如下所示:
- 手写一部分prompt模板信息
- 利用GPT3生成每个手动构造的模板的释义
- 回译生成的释义内容,目标是为每个任务获得大概100个提示
针对这些提示进行了实验,发现困惑度(PPL)越低,任务的性能更好。
ps:我怎么觉得这部分内容更像是demonstration formatting部分的内容,我不好说。
- Diverse Demonstrations Improve In-context Compositional Generalization
ps:大家的文章题目都起的这么直白,一眼就懂做的是啥了。
使用了不同的演示作为ICL的输入数据,提升了输入数据的多样性。
给了一张示例图,虽然完全没看懂画的是什么东西,但是看出来更多样的meta-train数据可以取得更好的训练效果。

本文多样性生成的一个出发点在于,预测局部结构比预测全局结构要容易很多,因此设计了一个算法来选择局部结构不同的实例;与此同时,在语义上,利用TF-IDF来计算出不同prompt的主题向量,计算其相似度来选择语义上的多样性。通过这两种方法选择多样性的数据用作prompt数据。
- Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
出发点在于,像前面的文章讲述的从数据集本身选择的demonstration会造成LLMs的高度依赖,因此本文直接让LLM(其实原文说的是PLM)自己生成demonstration,最小化对外部演示的依赖。
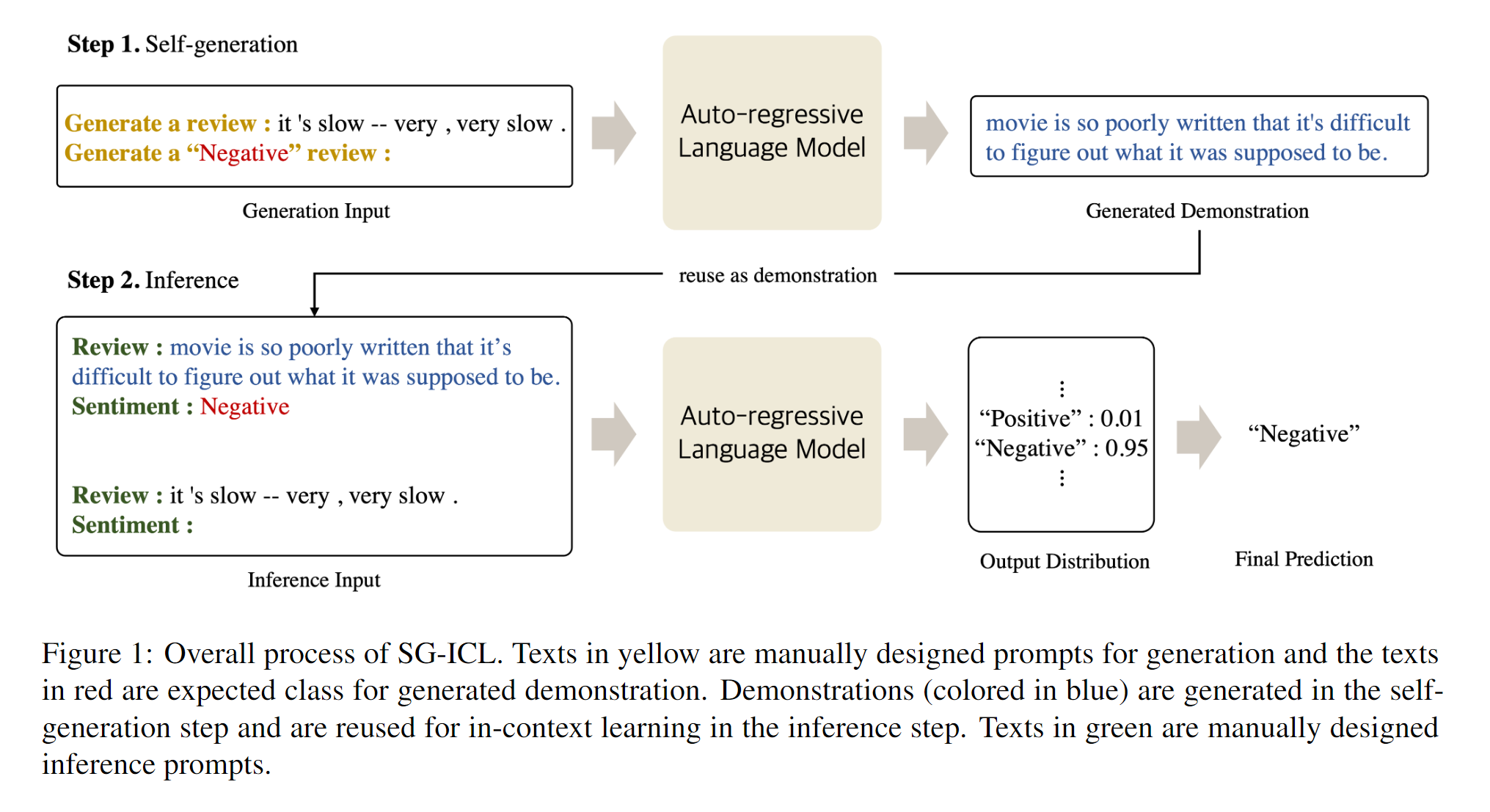
如上图所示,先让模型自己产生demonstration,然后直接拿来拼到自己产生的prompt当中使用。思路过于简单,就不细说了。
- Self-adaptive In-context Learning
思路很简单,先选择后排序,根据相似度等方法选择出部分候选demonstration,然后根据已有的demonstration进行排序,值得一提的是,他这里的排序使用了MDL(mininum description length),利用压缩完的码长决定已有的demonstration的排序。但是可惜我不太会信息论,这个部分没看懂。

- In-context Example Selection with Influences
主要的思路是,针对demonstration当中的某个特定的元素$X_j$,通过控制其是否存在来观察模型的效果,最终计算出该元素的作用。

算法也非常简单粗暴,拿出所有的子集计算一下效果,然后对demonstration当中的所有候选都按照是否存在计算一下效力,最终选用效力最强的一个组合。唯一不理解的地方在于,这里还计算所有的子集干嘛,似乎只能观察一下demonstration的个数对实验结果的影响。
- Finding Supporting Examples for In-Context Learning
抽象的做法,感觉思路对的,但是没讲清楚。对于一组已经存在的demonstration,记为$e’=(x’,y’)$,计算在所有这样的$e’$当中,是否算上$e=(x,y)$的效果影响,将这个效果影响称为$e$的Infoscore,把这个作为选择demonstration的依据。
当然,想要拿出所有的子集是有困难的,所以这里还用了一个简化,这里就不再赘述了。
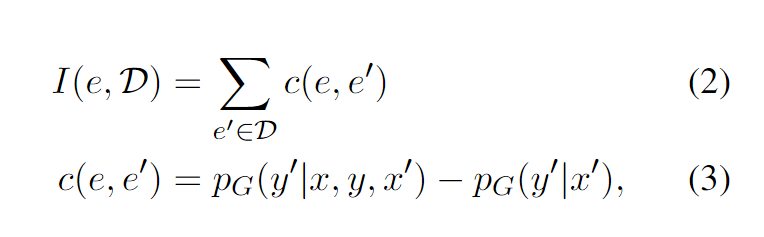
有监督方法
- Learning To Retrieve Prompts for In-Context Learning
使用了注释的数据,根据LMs上候选demonstration的效果,从而将这些demonstration标记为正例/负例。
主要分为两个阶段,先按照表面语义选择出和候选示例语义比较相似的一部分候选demonstration集合,这么做可以避开$O(n^2)$的时间复杂度,将问题简化。
随后,在已经选出的所有候选集合当中,对于每个候选的演示,单独把他和示例丢进LMs观察效果,根据产生y的概率区分正负例,使用对比学习。

- Unified Demonstration Retriever for In-Context Learning
和上篇文章基本上思路一致,唯一的不同点在于,本文提出了一种统一的架构,可以把演示检索(Demonstration Retriever)统一到一个简单的统一结构上。
ps:好笑的是,上篇工作始终称之为prompt retriever,这里就改口为demonstration了。
这里提到,设计的UDR(Unified Demonstration Retriever)来源于DPR(Dense Passage Retriever),这里的DPR应该是一个简单的相关内容查找。
感觉思路还是很简单啊,把任务指示和示例拼接,在所有的任务指示+demonstration当中计算相似度。最终丢进LM当中看看效果,没看出有什么特别的地方。
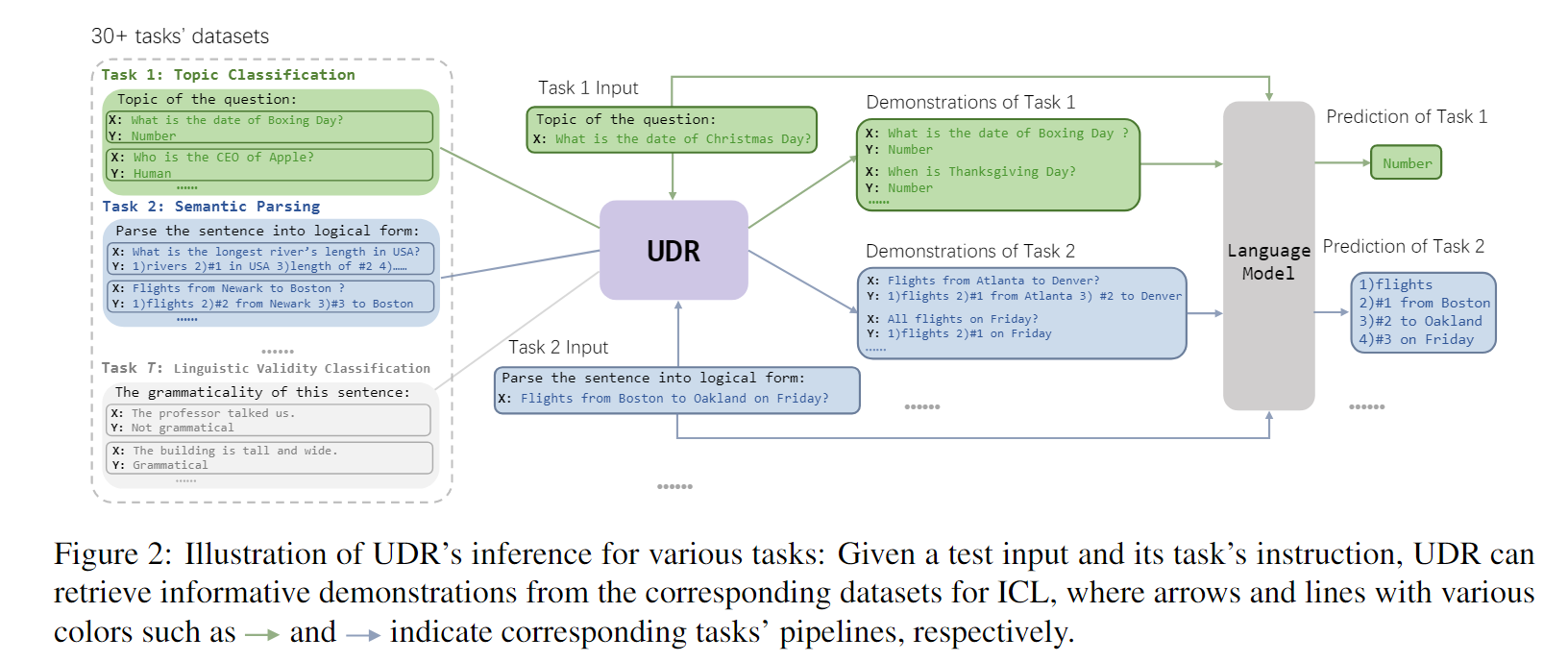
- Compositional Exemplars for In-context Learning
前面的两篇工作更多的局限在单个示例的内容,本工作应用了DPP(Determinantal Point Process)探索了整个数据集所有实例的联合概率和内在关系,从而对所有潜在demonstration整体进行建模。
但是因为不太懂DPP具体是个啥,所以只能简单的宏观上分析一下。
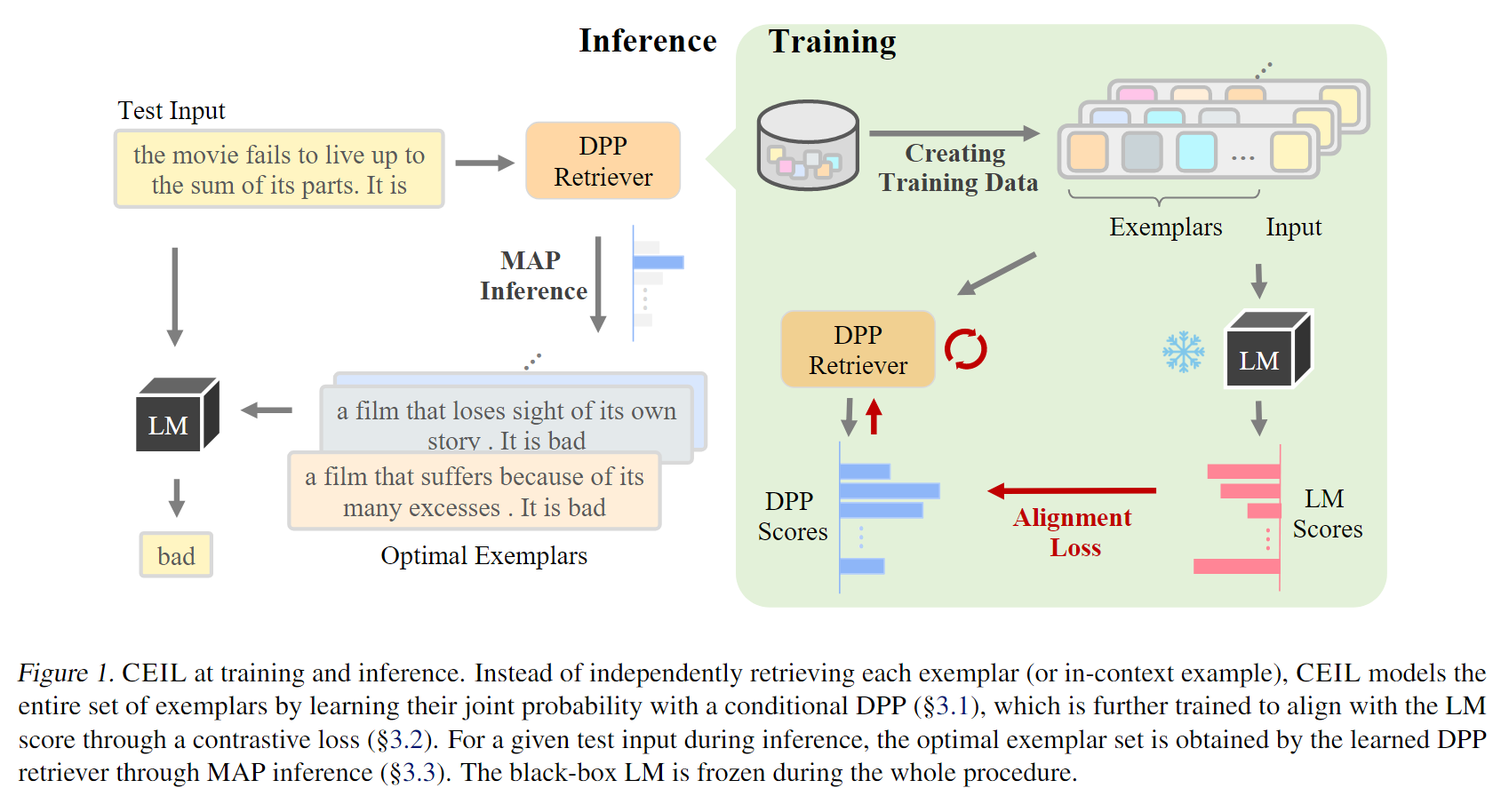
DPP是一种能get到整体特征的东西,本质上也是选择出较为接近的,且具有一定多样性的candidate demonstration,在训练的过程中,值得注意的一点是,对齐了LMs的分数以及DPP表现出的分数,通过这样的方法来训练DPP,但是具体还没完全搞清楚。
- Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
没特别理解,将一个任务的描述视作一个topic,可以从候选的demonstration的(x,y)当中提取相关信息,去优化了topic的选取(描述的看起来更像是向量化的说法),这篇文章还需要仔细阅读一下。
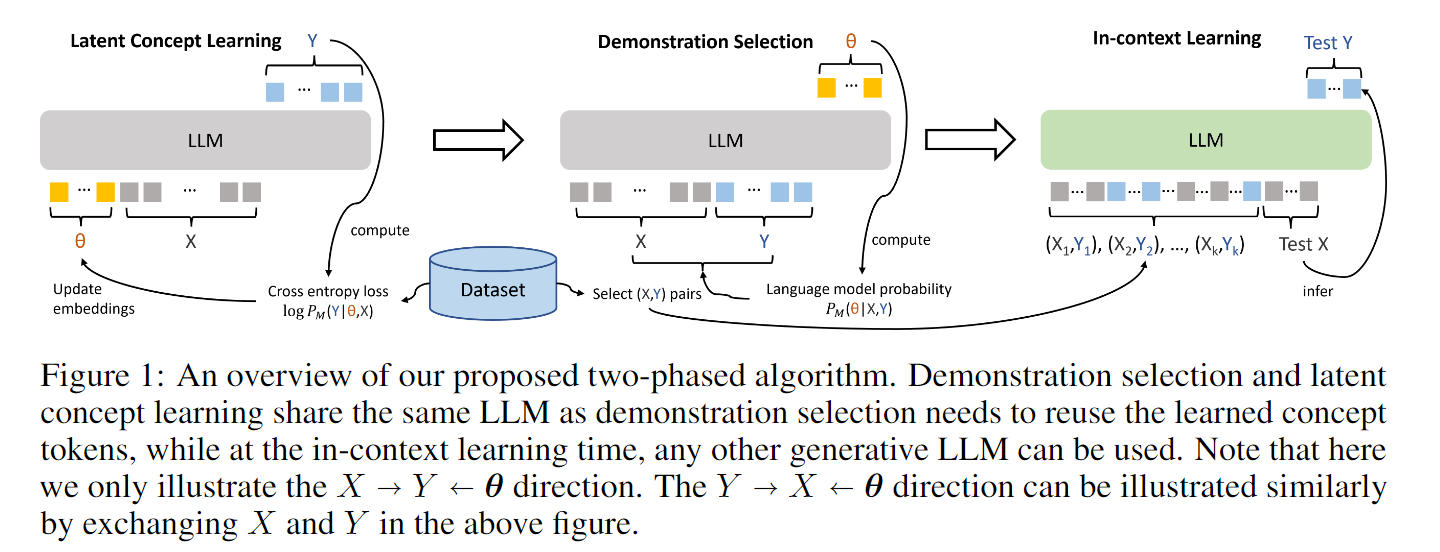
这里也给出综述对于这篇文章的叙述,后续自己需要再阅读一下。

Demonstration Ordering
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
在选用的demonstration是一定的情况下,实际上demonstration的排列顺序可以对整个ICL的效果产生较大的影响。本文研究了顺序的现象,发现特定的顺序特定于模型结构,本文根据熵的统计信息来选择demonstration的排列顺序。
本文首先探究了demonstration ordering的影响,发现即使是对于规模较大的模型来说,不同排列的方差还是很大的,也就是说,对于整体的效果来讲,即使是大模型,不同的排列顺序的效果差异很大。
此外,本文发现通过添加训练样本也不能减少顺序的影响,同时,在特定模型上适用的demonstration & demonstration ordering无法轻易迁移到另外的模型上(即使是从GPT2-XL到GPT2-Large)。
本文的探索流程基本分为如下几步:
- 针对demonstration的候选全集$\mathcal{S}$,找到其每一个排列,作为候选demonstration ordering
- 对于每种排列,构造探测集
- 针对不同的探测集,放在LLMs上检验效果,再进行排序
第一步原文繁文缛节的叙述了一下,我觉得什么都没讲,就是构造了一系列候选的demonstration。对排序分析的时候主要考虑了Global Entropy以及Local Entropy。
这里偷个懒,先用网上的解析。

Demonstration Formatting
常见的ICL技术,就是仅仅将示例和标签相连,再转换为特定的模板。然而在特定的复杂推理任务当中,仅仅将示例和标签相连对模型来说还挺难的,例如数学推理和常识推理问题。因此这里其实会在示例和标签当中添加部分中间推理(intermediate reasoning)步骤。
Instruction Formatting
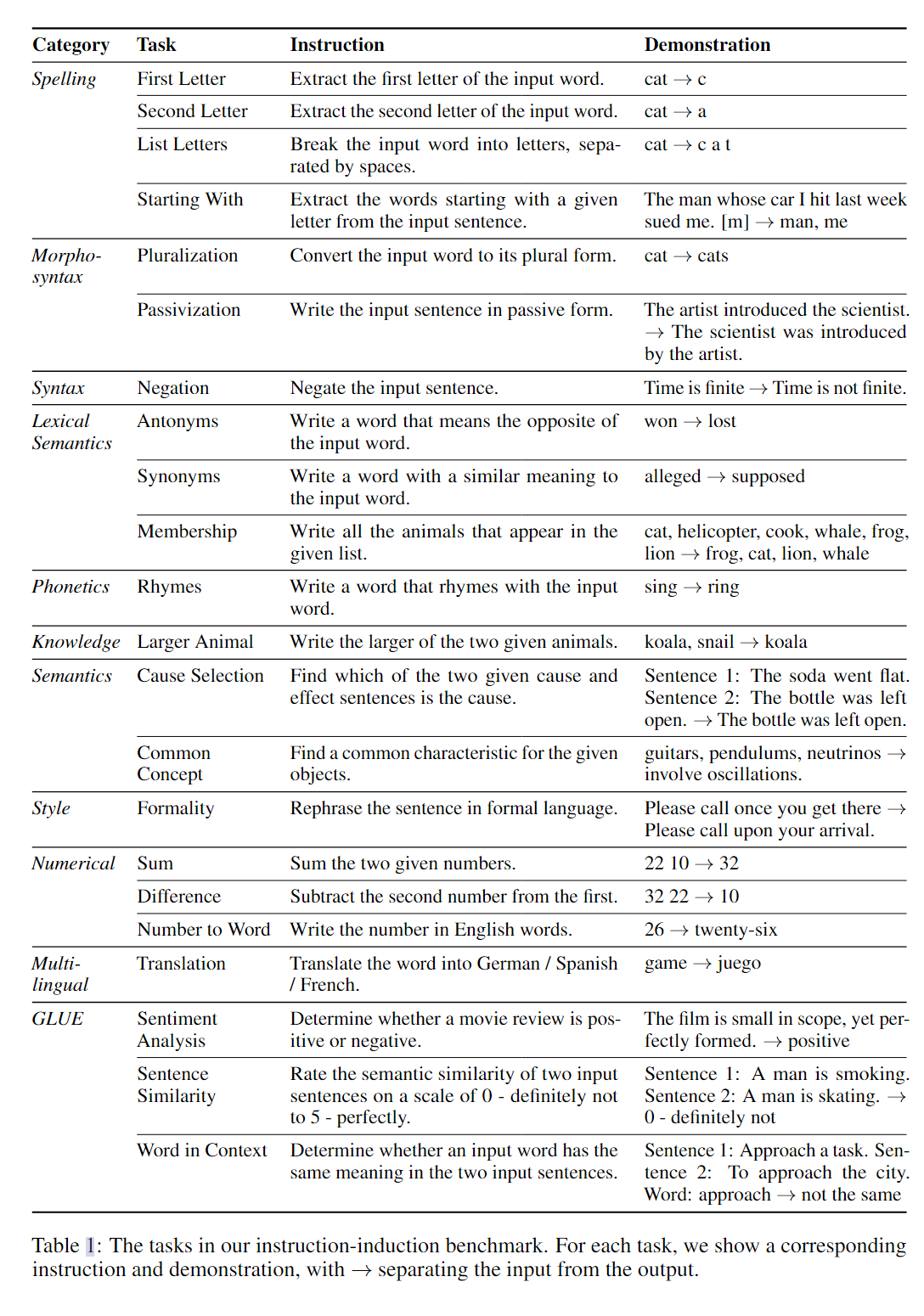
- Instruction Induction: From Few Examples to Natural Language Task Descriptions
出发点:论文的出发点本质上是想探索ICL(当然,这里针对的是根据特定的任务生成任务描述)的能力,通过设计了一个新任务做这件事。
如下图所示,所面向的任务实际上是根据给出的context内容,归纳出任务的具体描述。
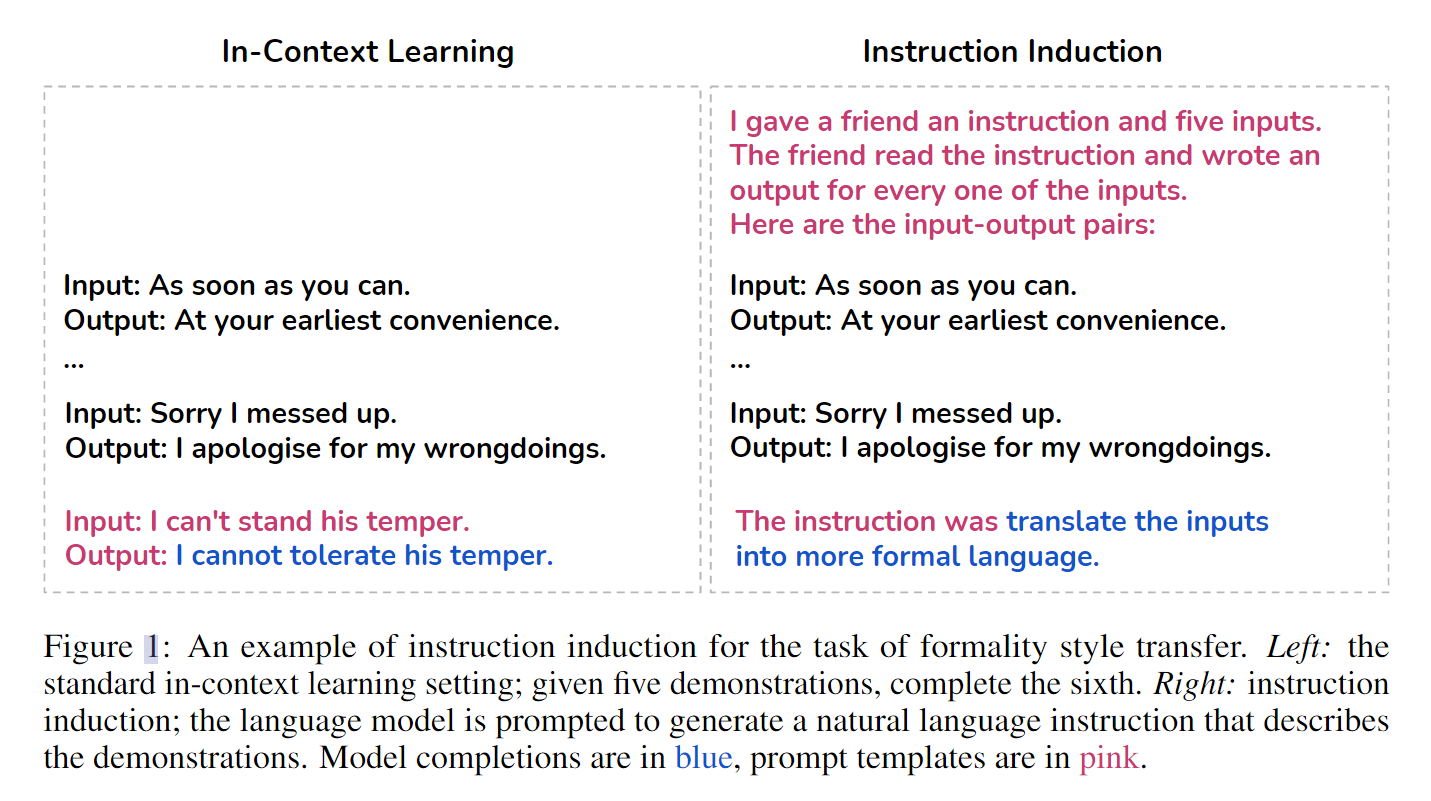
针对一些特定的任务描述设计了指令归纳的任务,最后通过BertScore进行了分数的评估,值得注意的是,其中也包含了一些很有挑战性的任务描述,例如风格转移,包括甚至使用一到五的分数来评估某个句子的相似程度。
- Large Language Models are Human-level Prompt Engineers
出发点:在ICL学习当中,指令的描述通常由人类自己编纂,受到人类编纂的启发,本文设计了自动提示工程师(Automatic Prompt Engineer,APE)用于自动指令生成。
本文主要的方法分为两个部分,在生成指令部分,本质上是一个搜索LLM提出的指令集合,并且进行优化的程序;在评估指令的部分,实际上是通过另外一个LLM的实际效果来衡量的。
第二个部分很好理解,主要针对第一个部分说明,作者把LLM产生指令看作一个黑盒的优化问题。
下图当中$\rho$是针对任务的指令,Q是一系列demonstration,A是LLM的回答(应该是说正确的回答),因此想做的事情是最大化LLM正确回答的概率,$f$是对这个指令的评估分数。
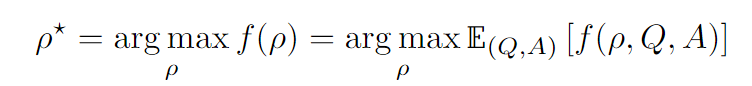
下面这个比较抽象,针对指令的优化,本文主要分为了两种策略,前向的策略和反向的策略。对于前者,其就是把空缺部分放在最后,对于后者,是把空缺部分放在前面(使用填充式的LMs,比如T5)。

同时,使用优质指令的周边指令:

- Self-Instruct: Aligning Language Model with Self Generated Instructions
出发点:和前文类似,将零样本泛化到新任务的ICL能力大多依赖于人类编写的demonstration,但是因为是人类写的,所以数量和多样性上都有局限,因此这里做的事情实际上是想通过让LLM自我迭代的产生特异于任务的更好instruction。
如下图所示,思路很清晰:
- 构造一个seed task集合
- 随机sample task
- 丢给LLM,让他进行辨析,生成instruction和demonstration
- 过滤,返回到task集合本身

没有什么特别好讲的,这里唯一需要注意的是,为了保证多样性,引入了ROUGE-L指标。
Reasoning Steps Formatting
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
出发点:根本原因是想提升大模型的复杂推理能力,目前的模型针对复杂推理的能力十分有限。
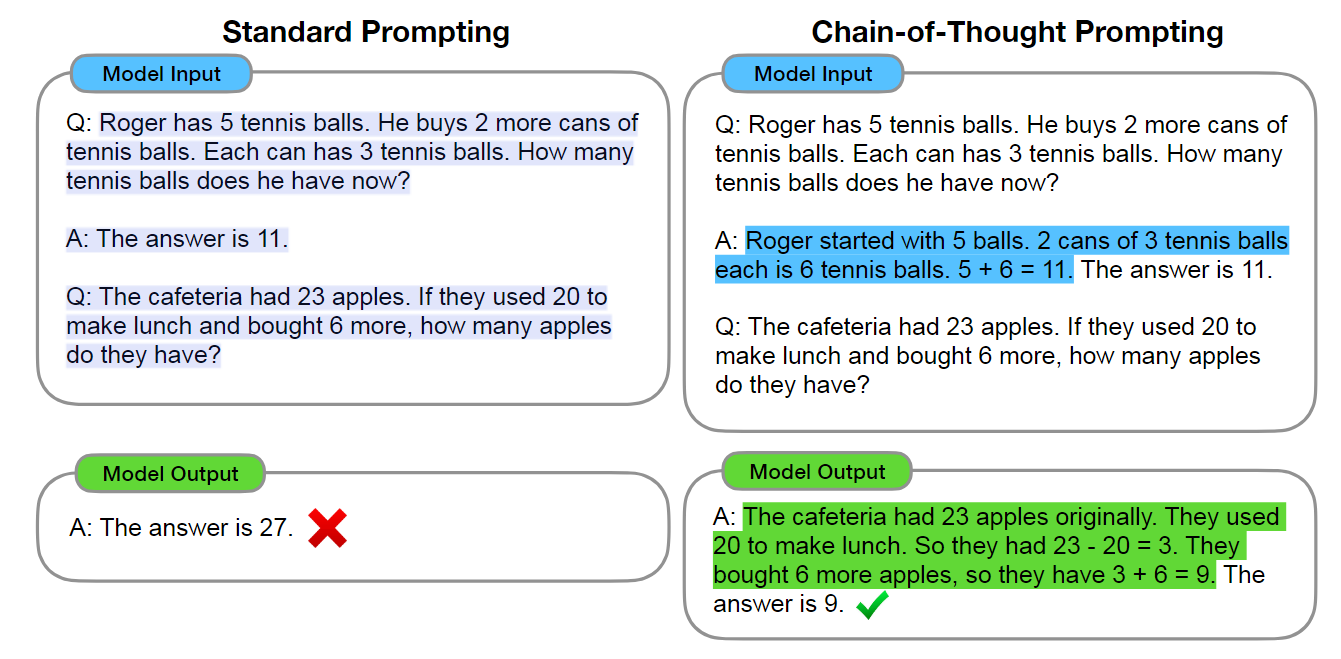
这篇文章就比较出名了,方法也很简单,在给定demonstration的同时给出chain-of-thought的思维链,发现在复杂问题上远远变好了。
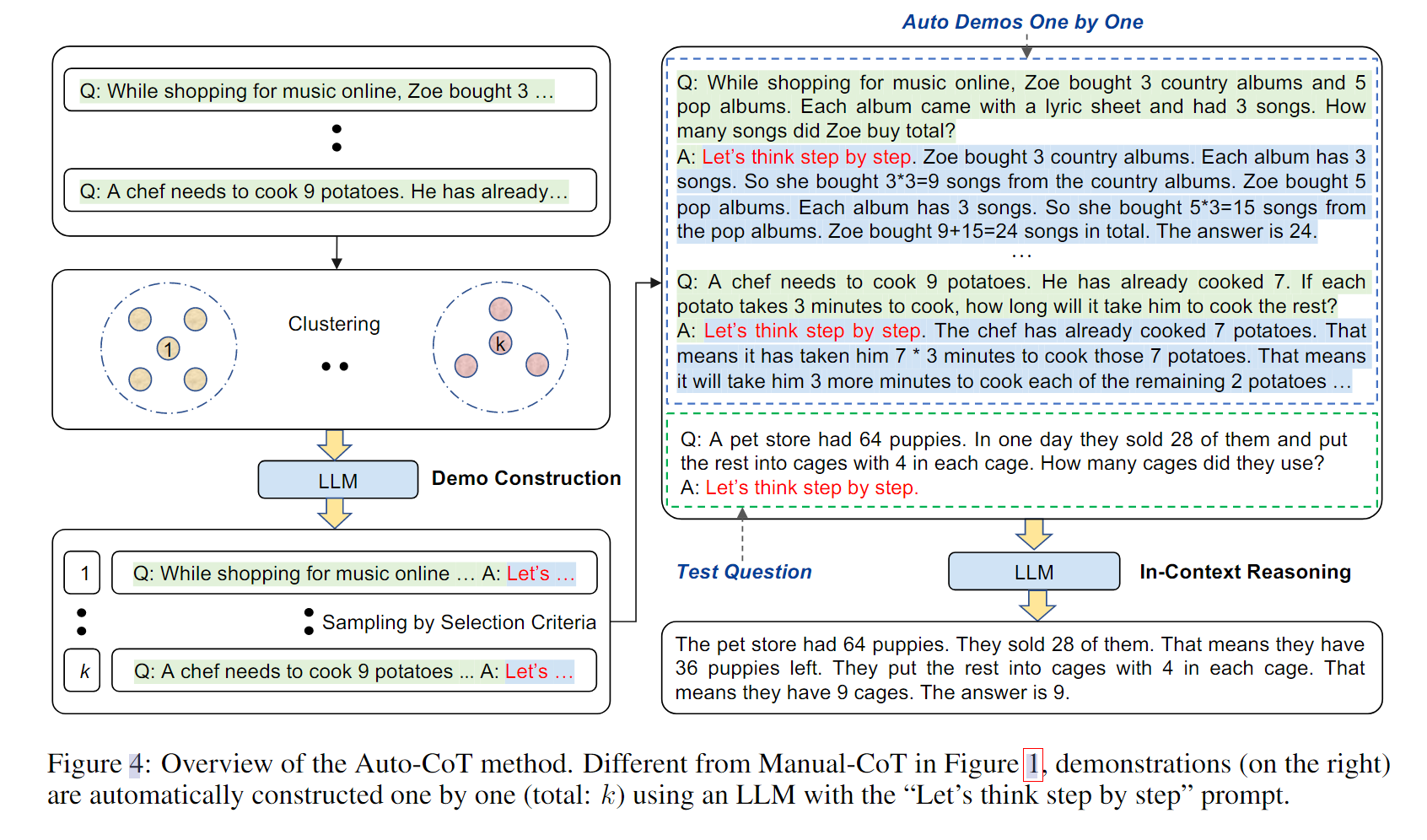
- Automatic Chain of Thought Prompting in Large Language Models
出发点:主要的出发点来源于,推理链在构造的过程中也很依赖于多样性,因此使用了一种多样性的策略来自动构造思维链。
可惜的是觉得这篇文章的工作思路比较单一,真的是用了一个prompt去针对每个问题聚类产生了CoT。而且在具体实验上也仅仅是使用了$Let’s think step by step$这样的魔法prompt。
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
出发点:本文动机提出了一个有趣的观点,ICL学习在尝试解决比demonstration更困难的问题的时候不能有很好的效果。本文的提示思路是,将复杂问题分解为系列简单的子问题,然后顺序求解。本文的名字也比较有趣:Least-Most Prompting.
具体的思路就如下图所示,也比较简单,先把原先的问题分解,然后在LMs回答出上次的问题的时候,可以尝试将上次问题的答案重新和问题本身作为一个新的context,来指引学习。
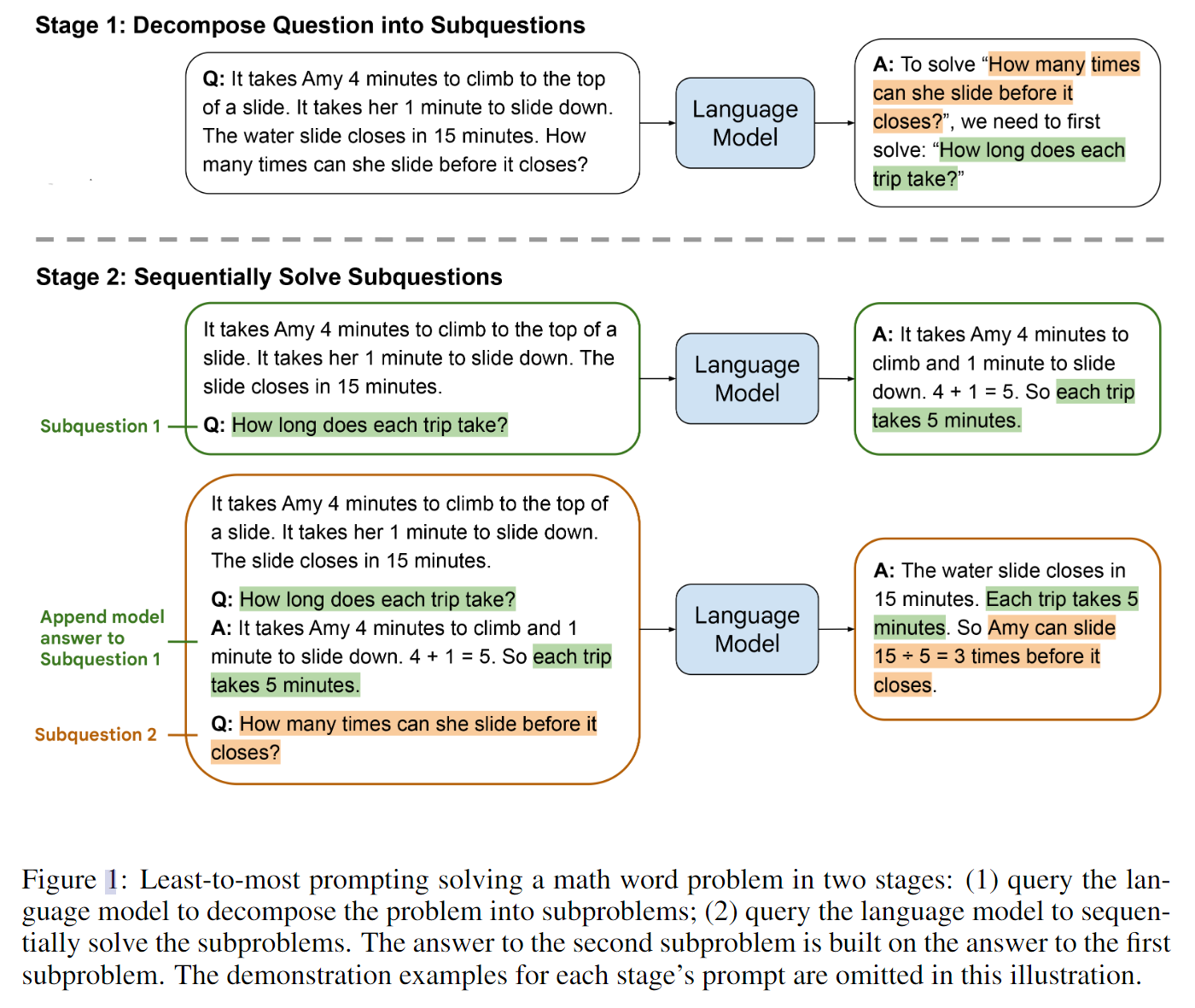
文中举了一个例子,具体说明demonstration比实际问题简单的时候的效果。

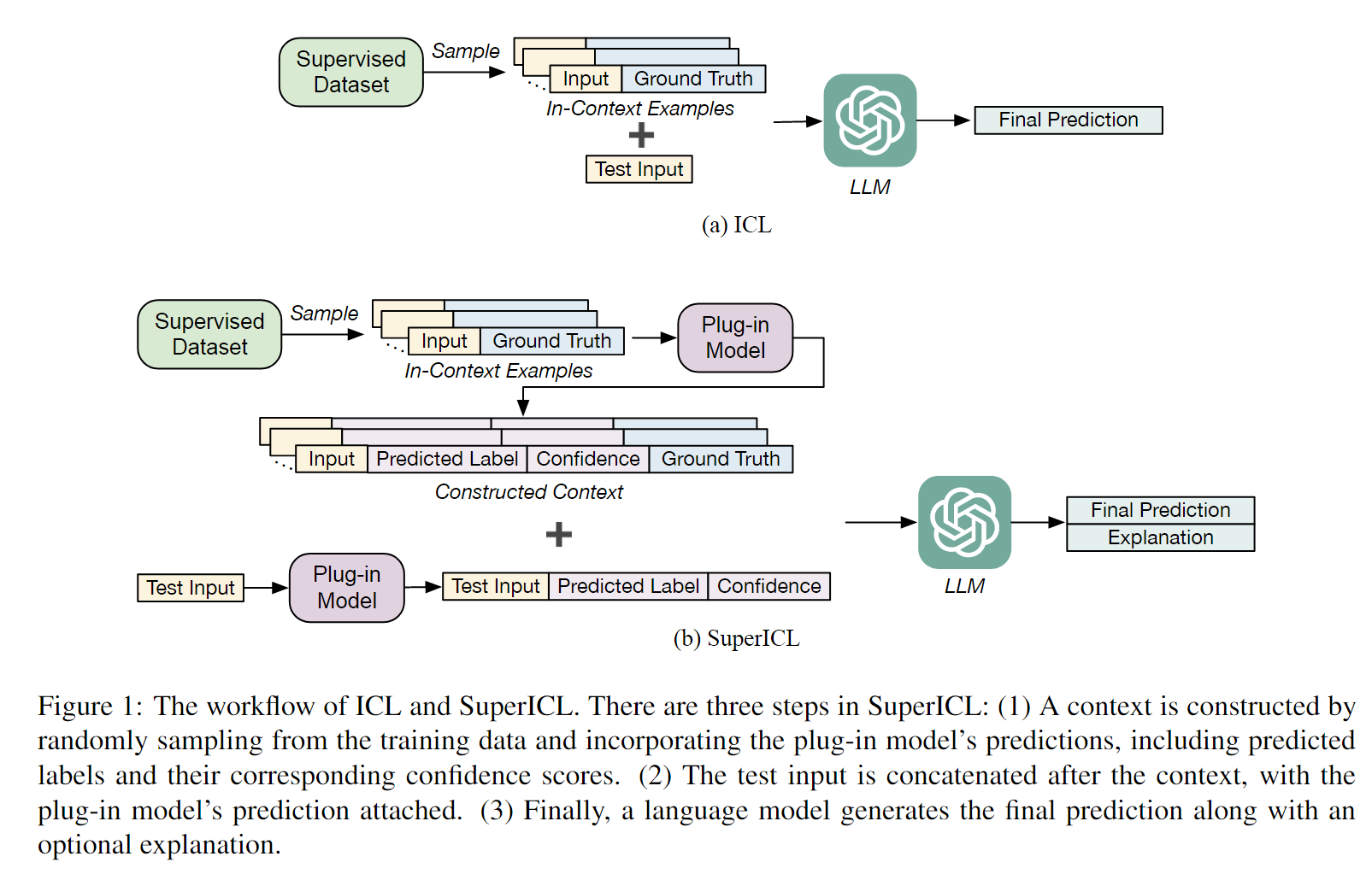
- Small Models are Valuable Plug-ins for Large Language Models
出发点:部分局部微调的小模型在特定的任务上表现很好,因此把LLM拿来作为黑盒,和局部调优的小模型共同工作,在特定的任务上会取得更好的效果。同时可以让ICL稳定下来,也能增强小模型的表现能力。
很简单的思路,本文之前貌似也被推荐过,所以是略微看过一遍的。
思路就是把小模型的预测和置信度都丢给大模型作为参考(作为大模型的ICL),提升大模型的表现效果。
Scoring Function
这一部分其实是对评估方法上做改进,但是文章很少,也确实没有什么特别有价值的可以直接拿来利用的部分(前面的文章基本也都包含了),暂且搁置一下。