Improving In-Context Few-Shot Learning via Self-Supervised Training
Improving In-Context Few-Shot Learning via Self-Supervised Training
主要思路
ICL学习很强,但是想将ICL学习直接应用于LLM上不太好,可以通过引入一个intermediate traing stage来提升模型的ICL表现,因此作者设计了四种中间训练阶段来辅助ICL学习。
Methods
定义输入输出实例
对于每一个input-output pair对,使用两个特殊标记附着在原有的文本前,其中两个文本也由<\newline>这样的特殊符号来分隔开来。
同时,对于每一种不同的任务的多个实例,中间也用newline来分隔开来,更靠前的实例就是用作演示的任务示例,从而实现高效的计算(不知道高效到哪里了,感觉这么做是很自然的想法)

构建训练实例的时候,实际上是使用三个或更多的连续句子,然后根据不同的特定预训练任务自动创建训练数据,损失函数貌似直接使用了交叉熵损失。比较神奇的做法。
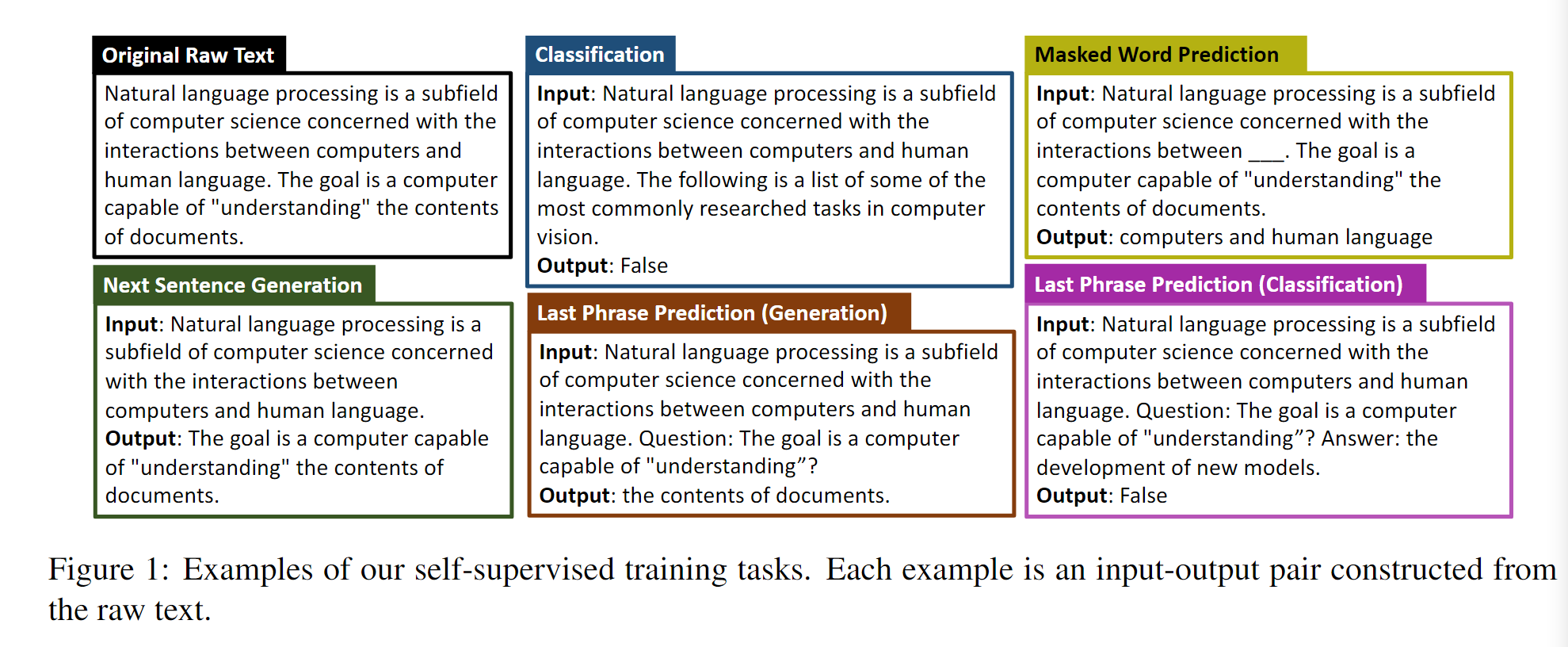
Next Sentence Generation
使用最后一个句子作为输出,其他的句子作为输入,预测最后一个句子的生成任务。
Masked Word Prediction
随机替换输入句子当中的word,预测被mask的单词,将被mask的单词作为输出。
Last Phrase Prediction
去掉最后一个短语作为输出,这里用了question:和?作为标记,将答案前面加上了answer:。
此外,创造了一个功能词的表格,来识别句子的最后一个短语,从功能词开始的文本段视作最后一个短语。
Classification
创造了一个分类任务,对于这个任务的输入,考虑了四种不同的情况:原始句子,打乱的句子,来自一个不同文档的句子,来自多个不同文档的句子。
在构造训练实例的时候,随机选择了一个或两个额外的输入类型,并把它们与原始句子结合起来形成了二元或三向分类任务。
虽然没特别看懂,但是他构造了一些分类任务来判断文本的主题 内容,理解了他的内涵。
总结
虽然方法很新颖,但是要调参数,不适用于chatGPT。
本文由作者按照 CC BY 4.0 进行授权