Multilingual LAMA, Investigating Knowledge in Multilingual Pretrained Language Models
本文的主要动机来源于,发现多语言的背景下,LMs会表现出语言偏差,例如使用意大利语,会倾向于将意大利预测为原产国。
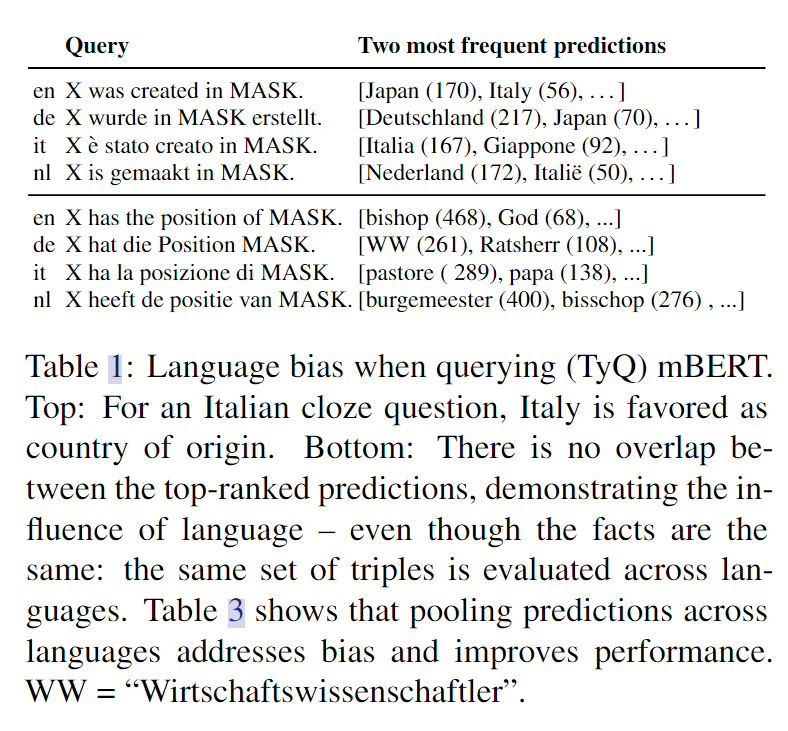
例如上图,可以看到语言的倾向是很大的,会对预测结果产生较大的影响,本文针对这个问题,利用mBERT做了以下问题探究:
- mBERT可以作为多语言知识库,大多数先前的工作只考虑了英语,将研究语言扩展到不同语言同样重要
- 利用英语数据集的翻译,探究mBERT的性能和语言有关
- 多语言模型被在更多文本内容进行训练,mBERT能否发挥这一优点
本文的主要方法如下所示:
选取了已有的数据集TREx,GoogleRE,自动翻译为了多语言版本(包括53种不同的语言);
针对已有数据集当中的三元组做处理(对象,关系,主题);
针对原有数据集的内容,将填空查询替换为了排序。
本文由作者按照 CC BY 4.0 进行授权