一些有关跨文化差异的文献简单总结
写在前面
找到了一些努力的方向,希望自己能尽快发现科研的乐趣!
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
摘要
提出在多语言下的多文化问题,尝试捕捉跨文化的价值观。将Hofstede文化维度理论和世界价值调查应用到了大规模语言模型的文化差异的评估上。
13种语言,13种国家。
主要贡献:
- 我们提出了第一个测量嵌入在大型预训练语言模型中的文化价值的研究
- 我们提出了一种通过将调查问题转换为完形填空来探测值的方法
- 我们使用三种语言模型(mBERT、XLM和XLM-r)在13种语言上进行了实验,通过两次大规模的价值调查显示了价值对齐相关性
- 我们围绕在多元文化背景下部署这些模型的潜在影响进行了讨论
可恨的是,代码没开源,去年三月份到现在都没开源了。
相关工作
很多人研究过毒性信息和常识推理,以及社会当中包含价值观等有偏的信息,这里甚至做了多模态。
据他所说,没有研究搞过跨文化的价值观评估。
探索价值观
主要提出了三个问题:
- 预训练模型是否捕捉到了既定价值观的跨文化多样性?
- 不同预训练模型的嵌入是否有相似之处?
- 预训练模型当中嵌入的价值与现有的价值是否有关系?
价值调查
给出了两个不懂的词,Hofstede的文化维度理论和世界价值调查。
文化维度理论
用了六个文化维度,分别是权力距离(pdi),个人主义(idv),不确定性回避(uai),男性气质(mas),长期取向(lto),放纵(ivr)。对于每个问题,Hofstede给出了定义的公式。总而言之,通过一些方法将文化映射到了国家。
世界价值观调查
以更详细的方式收集跨文化人群的价值观数据。这项调查开始于1981年,由一个非营利组织进行,其中包括一个国际研究人员网络。这项调查是分阶段进行的,目的是收集价值观随时间变化的数据。最新的浪潮是第七波,从2017年持续到2020年。与欧洲价值研究2相比,WVS针对所有国家和地区,包括57个国家。
大概就是问问题,WVS公布了每个问题的调查结果。这些分为11个类别:(1)腐败,(2)道德价值观和规范,(3)幸福和福祉,(4)移民,(5)政治文化和政权,(6)政治利益和政治参与,(7)宗教价值观,(8)科学和技术,(9)安全,(10)社会资本,信任和组织成员,(11)社会价值观,态度和刻板印象。
探索生成
为了使调查与语言模型兼容,我们将调查问题重新制定为完形填空。简单来说,感觉是去问PLMs的完型填空问题了。
文化维度理论 & 世界价值观调查
把设计的问题变成了hard prompt的题目,评价为啥也没干。

跨多种语言检测
使用半自动的方法,将创建的探测从英语翻译成目标语言,我们使用一个涵盖所有目标语言的API。
(未完待续,现在这周还剩一天了,我还要看七篇,哈哈)
这里实际上使用的方法是使用模型将英语翻译为目标语言,将上文当中的模板方法当中的[MASK]换成标签词,来帮助保持语法结构,从而帮助翻译模型。为什么作者不自己重新翻译一遍呢,因为有人指出,翻译调查问题的时候会出现问题丢失(虽然不知道为什么用他这种方法就不丢失了8)。
在将问题由英语替换到目标语言之后,我们首先通过一些方法来检查替换后的翻译的标签,在检查的过程当中,我们实际上使用了跨语言单词对齐器,来对齐英语的词汇和对应语言当中的词,虽然没有解释这是什么东西,但是根据语义感觉还挺好理解的?比如英语当中的某些单词可能需要用其他语言当中的不止一个词来表示。最终当然还得把找到的目标词换回来,比较好笑的是,如果两种方法都没有找到目标词的话,还是得人工操作。

语言和国家的选择
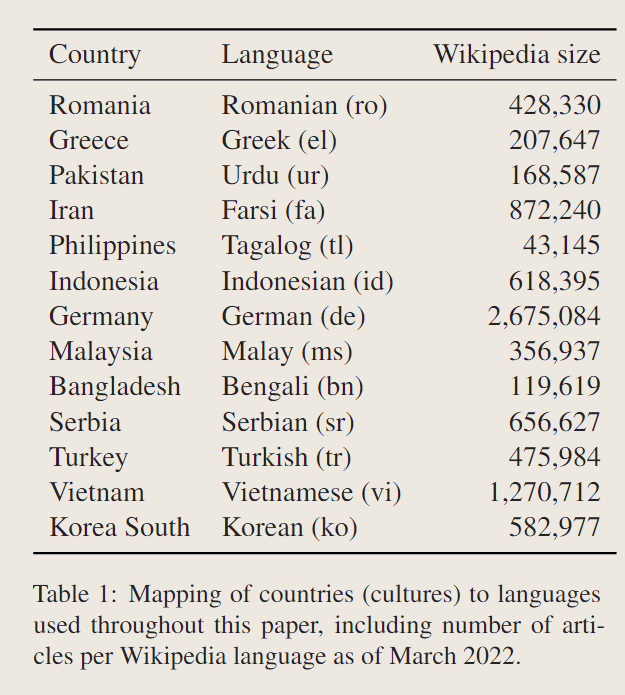
选取的标准是,被之前文化层面的文章调查过,而且存在于mBERT,而且在wiki上有超过10000篇条目。
方法
模型
总而言之,选了一堆多语言模型,主要是:mBERT、XLM(MLM version)、XLM-RoBERTa。
Mask探测
没太看明白,貌似是这样的,人工标数据的时候是从1-10分标注的,所以模型评估的时候也用了一个最大概率和最小概率的对数差。同时对每一个相应问题的所有回答的量进行了归一化。
评估
计算了模型回答的和人回答的值之间的等级相关系数。
结果
仍然是根据前面所说的三个问题来计算:
- 预训练模型是否捕捉到了既定价值观的跨文化多样性?
- 不同预训练模型的嵌入是否有相似之处?
- 预训练模型当中嵌入与现有的价值是否有关系?
RQ1
显示出了不同文化的价值观差异,由于本文用了两种方法,即WVS和Hofstede的六维方法,六维度的表现不明显,而WVS的效果还不错。
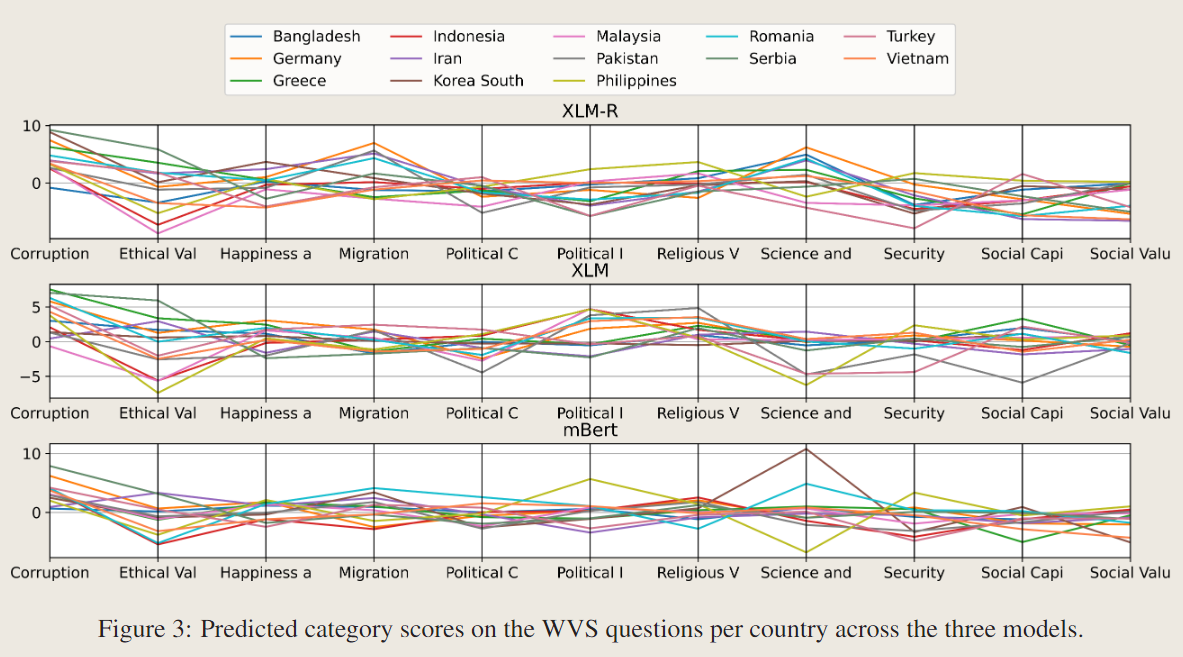
RQ2
相关性很低,基本上没啥关系。不同的训练任务会得到不同的嵌入。
RQ3
对于Hofstede的六维理论,相关性很弱。
对于WVS,貌似也没啥关系。
(绷不住了)
Wikipedia Cultural Diversity Dataset:A Complete Cartography for 300 Language Editions
摘要
在本文中,我们介绍了维基百科文化多样性数据集。对于每个现有的 Wikipedia 语言版本,数据集包含表示其相关文化上下文的文章的分类,即与语言相关的所有概念和实体以及它所说的领土。我们描述了用于对文章进行分类的方法,以及我们定义提供分类器的丰富特征集,并作为数据集的一部分发布。我们提出了几个目的,我们设想使用这个数据集,包括检测、测量和反击维基百科项目中的内容差距,并鼓励数字人文领域的跨文化研究。
简单来说,造了一个多语言的上下文相关的数据集,旨在得到CCC(与编辑的地理和文化背景相关的文章(即他们的地点、传统习俗、语言、农业、传记等)文本。
数据集的创造
语言-领土映射
将语言和第一第二层次的政治划分相关联,当一种语言仅在国家的部分地区使用的时候,才使用二级层次。用ISO代码进行了识别。
特征描述
当我们得到前一步的结果后,我们将会获得文章和语言之间的关系(虽然前面说的是地域吧)。
定义了一些文本特征,来描述一个文本是不是CCC文本。有好多好多,通过(1)一定是;(2)有可能是;(3)一定不是;(4)有可能是;来衡量是否是CCC文本。

机器学习
使用随机森林分类器来学习给出的所有特征来限制是否得到CCC文本。将类别1视作可靠的CCC文章,类别0视作可靠的非CCC文章,当然也有文章同时存在两个属性,不过很少。拿到所有的类别1作为最终选择。对于负样本,用了负采样的方法,将所有不属于类别1的文本内容拿出来五个视作样本0,也就是说,我们的分类器最终训练的是属于类别1的文章和随机文章(而不是简单区分CCC文章和非CCC文章)。
手工评估
相较于之前的工作,做了一次更大的人工评估。
主要归因
我们找到的CCC文章占据了不同语言的不同比例,当然也包含了很多区域,我们设计了一个简单的启发式方法来估计每个文章被归因到了多少特定的领域。
- 地理代码代表的地区
- 文章中包含的关键词
对于其他的CCC文章就用一些别的方法去分,但是没仔细看。
数据集描述
用了CSV格式存储,最大的文件是英文wiki(265MB),整个数据集是1.67GB。
该数据集可在 Figshare 和 WikipediaCulturacy Diversity Observator 上找到。它也以所有语言(称为 ccc_old.db)的单个 SQLite 3 数据库的形式提供,它们占用 9.5GB。
数据集结构
列举一个大概的图,就不详细说了。
应用
主要强调了三个方面的应用:
- wiki文化差距评估和改进
- 数字人文领域的学术研究
- 用户生成的基于内容的技术
然后详细说了各个应用的内容,这里就暂时不多介绍,不详细读了。
结论和未来工作
使用本文提出的数据集,我们希望消除维基百科中识别和促进文化多样性的一些主要障碍,以及刺激数字人文领域的跨文化研究。这些是维基百科文化多样性项目最重要的目标。该数据集可用于 300 种语言版本,并包含每篇文章与附近地理和文化实体的关系的细粒度分类,即深入了解不同语言社区如何自行定义。
发布的数据集包括分类器使用的所有特征,这些特征构成了从 Wikimedia 数据库中提取的元数据的宝贵丰富。还发布了用于处理数据并创建数据集的所有代码,以及手动评估的结果。算法和人类评估者之间高度一致表明分类的可靠性。
未来的工作主要分为以下几个方面:
- 每月创建数据集的完整自动化
- 使用新功能丰富数据集
Using Natural Language Processing to Understand People and Culture
(写在前面,这文章还得授权下载,但是这次同济大学支楞起来啦!)
摘要
本文概述了自然语言处理,以及如何使用它来加深对人和文化的理解。我们概述了语言的双重作用(即反映生产者的事情和影响受众),回顾了一些有用的文本分析方法,并讨论了这些方法如何帮助解开一系列有趣的问题。
这篇文章提供了一个关于如何使用自动文本分析来阐明人和文化的综合讨论。它回顾了最近的方法,并解释了它们如何被非专业人士应用来回答一系列研究问题。
感觉是一个泛泛而谈的文章。
引言
语言无处不在。它是人们表达思想、与他人交流以及消费新闻、故事和信息的方式。这就是父母如何养育孩子,领导者如何领导,销售人员如何销售。语言是医生与患者沟通的方式,研究人员与研究参与者沟通的方式,政策制定者说服公众的方式。
毫不奇怪,语言有潜力告诉我们很多关于人和文化的信息。它可以深入了解人们是谁(例如,个性),他们的感受,他们的态度,观点和反应。此外,当在个体之间聚合时,语言可以揭示群体或社会文化背景之间的差异,以及为什么有些东西(例如产品或想法)会流行起来。
随后,作者表明了语言存在丰富的信息。而自然语言处理是做文本分析的好帮手。简单来说,作者说明了NLP的重要性。
本文概述了NLP,以及如何用它来加深理解,以及讨论了一些如何用这些自然语言处理的方法解决一些有趣的问题。
语言的两重作用
主要给出了两重作用。
- 反映了关于产生它的人或者人群的事情
- 影响使用这些语言或者文本的观众
语言反映制作人
简单来说,语言可以反映语言制作人的状态特征等,作者说,语言甚至可能预示着即将到来的分手(我没想到的是这还有文章出处的)。

由一个群体或社会文化语境产生的语言反映或表明了关于产生它的群体或语境的事情。
总结,分析语言不仅可以反映说话的人或者群体的情况,还能洞察社会文化差异。
语言影响听众
作者一开始举了几个例子,隐喻的方式传播的短语更加容易被人记住,而不确定的语言可以增加注意力。不同类型的语言会有不同的影响。
综上所述,关于语言影响的研究提出了鼓励注意力、说服力或记忆力的方法。此外,它还揭示了文化上的成功。因为语言会影响消费它的观众,包含特定类型语言的项目可能会更成功。
解锁文本的潜力
主要是两个方面,一方面可以提升对数据的访问;另一方面,由于海量的数据存在,我们需要借助自动文本分析技术来帮助我们处理数据。
随后,作者介绍了几种常用的自动文本分析技术,包括字典,主题建模,嵌入和神经网络模型。
由于本文章貌似不是计算机科学类的文章,因此他对于各个方法的介绍都很详细。
讨论
语言无处不在。在醒着的时候,人们几乎每时每刻都在以某种形式创造或使用语言。语言反映了产生它的人和社会经济背景,并影响了消费它的观众。因此,语言有可能更广泛地揭示人类和文化。
但要实现这一潜力,就需要合适的工具。
这就是自然语言处理的用武之地。这些方法不仅可以以相对客观的方式解析语言的特征,而且可以大规模地这样做。因此,这些方法可以阐明一系列有趣的问题。
中间说了很多有的没的,结论是:自然语言处理允许研究人员提出新问题,并以新的方式研究古老的主题。希望更多的心理学家会采用这些工具,并开始从文字中提取智慧。
评价为:什么都还没说呢就结束了,不愧是人文领域的文章x
Probing Pre-Trained Language Models for Disease Knowledge
这貌似是个医学文章呀,怎么感觉不是很文化,不会是因为他的题目带有Probing吧(
摘要
现有的预训练模型,例如ClinicalBERT可以在推理任务上取得一定的效果,但是现有的评价标准MedNLI等标准包含的示例较少,我们需要更多的推理形式的样例来衡量语言模型的效果,于是作者提出了DisKne的疾病知识的评估新基准,通过一些方法添加了更多推理形式的样例,以供模型的评估。提出了这种标准后,再来看看现有的预训练模型,发现都不行了(多损啊)。
引言
预训练语言模型在特定的领域经常会取得不错的效果,我们更加在意的是,预训练模型真的学到了什么,以医学领域为例,文章提出的问题是,预训练模型到底捕获了什么医学知识。
然而,原文研究了最著名的医学NLI基准之后,仔细检查出了三个重要的局限性,即:
- (1)只有少数的医学测试用例实际上需要医学疾病知识,而大部分用例仅仅需要有关术语和词汇饿知识;
- (2)训练和测试用例往往涵盖相同的疾病,因此无法确定良好的性能是否来自预训练语言模型本身的能力,还是来自于训练和测试用例之间的相似性;
- (3)基于以上两点,作者认为baseline在MedNLI上表现好,仅仅是因为这个benchmark拥有可以利用到的人工信息(artefacts,我咋感觉一般写作artifacts),类似于通用的NLI基准。
因此,作者提出了DisKnE(疾病知识评估,Disease Knowledge Evaluation)作为评估生物医学LM的新基准,明确解决了上面的三个限制,构成了一个更可靠的测试平台来进行评估模型捕捉到的医学知识。DisKnE实际上源于MedNLI,这个新基准主要分为术语和医学知识两个部分的内容。
基于提出的DisKnE,作者发现所有的模型表现都不咋样(struggle),作者还发现术语方面整体性能高得多,不同模型之间差异小,而医学知识的捕获能力则针对医学类别和模型类别而异。本文的主要贡献分为以下几点:
- 提供了一个新的benckmark来衡量模型捕获到的医学知识;
- 分析了几个医学BERT的变体,发现都struggle with新提出的benchmark
- 发现现有的模型在医学知识的某些类别下表现很好,说明即使是强如MedNLI这样的数据集也有人工痕迹
相关工作和背景
介绍了在LMs当中编码的知识,生物医学当中的LMs,以及对抗性的NLI。值得一提的是最后一个,即对抗性的NLI,作者大致采用了一种类似于WordNet的思想,来用UMLS(医学的一套语言系统)来替换假设当中的疾病,因此称之为对抗性的数据集。
数据集构造
(写到这里,上次工程伦理一直在边上bbll的同学这次又坐到我边上了,真的很倒霉捏^^)
就像前文所说的,得到的DisKnE数据集本质上是从MedNLI数据集当中抽取出来的,主要针对目标是否患有疾病的实例。这句话说的有点晦涩,我个人的理解是这样的,由于MedNLI当中是一个推理数据集,我们主要从中选取“一些东西”$\to$“是否患有某种疾病”的实例。例如,我们可以通过“咳嗽”来推导“患有感冒”。在抽取出这些实例之后,我们需要根据识别蕴含函数所需的知识类型手动分类。这一章节的内容同时还讨论了生成反例的策略以及拆分训练测试集的策略(不能简单拆分的原因是,害怕模型从测试集和训练集当中的相似疾病做出学习,保证模型是学到了知识而不是学到了抄答案)。
选择蕴含关系对
主要的思想是从所有的蕴含关系对的全集开始向外删除,首先删去蕴含关系当中患者没得病的实例,然后将其余的实例所给的有关疾病的知识,根据UMLS所给的概念唯一标识符代码来分类;在做完这一步分类之后,再通过一定的规则和形式进一步分类,规则和形式这一步主要是如图所示的方法:
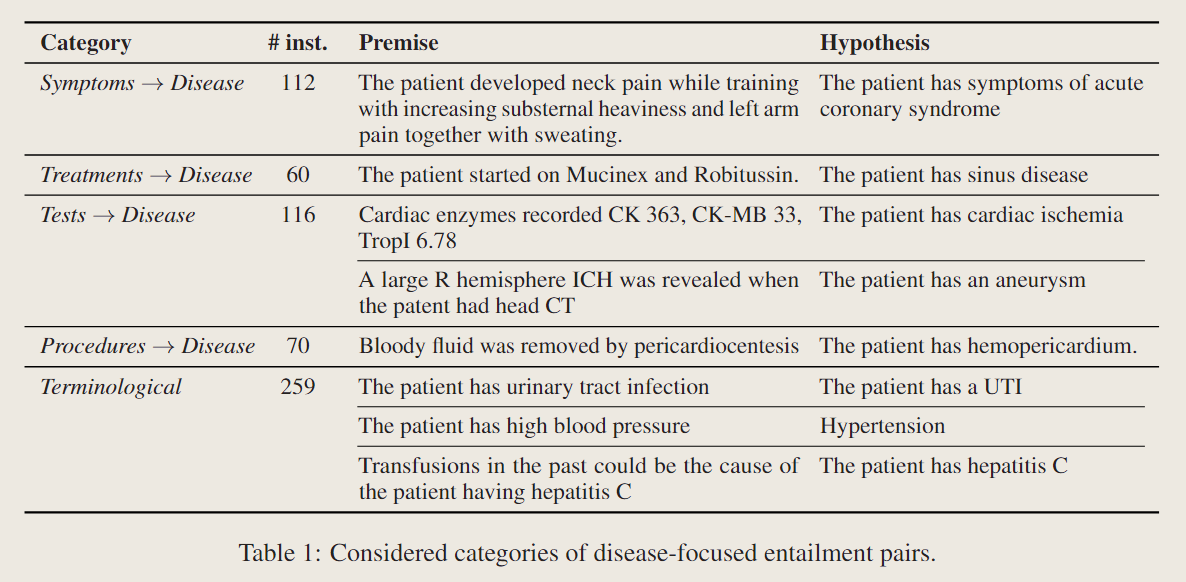
作者同时针对术语有关领域和医学知识有关领域的两个角度进行对比研究,针对医学知识这个方面,他表示和术语有关领域相比有四点不同,实际上就是把上面的表格又说了一遍:
- 症状到疾病类别
- 治疗到疾病类别
- 测试到疾病类别(这里的测试指的是拍片子那种)
- 程序到疾病类别(手术程序那种)
而对于术语领域,疾病在无论是前提还是假设当中都会直接提及名称,无论是缩写、同义词还是改写的句子,因此并不是非常需要知识支撑。
产生样例
在上一小节的内容当中,遗憾的是我们从MedNLI当中抽取的蕴含关系大多数只包含正例,而只有很少量的反例。处于这个原因,作者不直接从这些数据集当中选取负例,而是通过替换disease $X$来使用对抗的方式生成反例。具体的破坏方法,其实是从一系列候选的和$X$类似的疾病列表$Y_1,…,Y_n$,但不是SNOMED CT当中$X$的祖先或者后代(这里有关SNOMED CT,我也不知道这是个啥,但是简单的理解在于,我们不能选择一些同系列的疾病作为替换的目标,比如新冠两种不同的毒株?)。为了识别相似的疾病,我们使用了cui2vec的工具,这是预训练的临床概念的嵌入。此外,作者认为用来替换的疾病实例必须足够常见,不然会使得反例太容易被检测,因此我们只选择在其他正例当中出现过的疾病实例。
训练测试拆分
因为这个数据集的目的实际上是为了弥补其他数据集对于模型医疗知识考察的不足,因此,实际上我们是希望训练集和测试集当中的疾病是没有重叠的。换句话说,作者想要追求的是预训练当中模型学到的疾病知识,而不是训练过程当中学到的。
作者通过将正例当中的疾病以上一节的方法来替换为负例的方法来分别产生训练集和测试集当中的数据,详细的过程这里暂时没有仔细看,简单放一张图。值得说明的是,会根据$X$前面的冠词是$a/an$来同时指导用来替换的疾病名称$Yn$。
规范化
简单来说,对数据集当中的假设做了一定的规范化。
实验
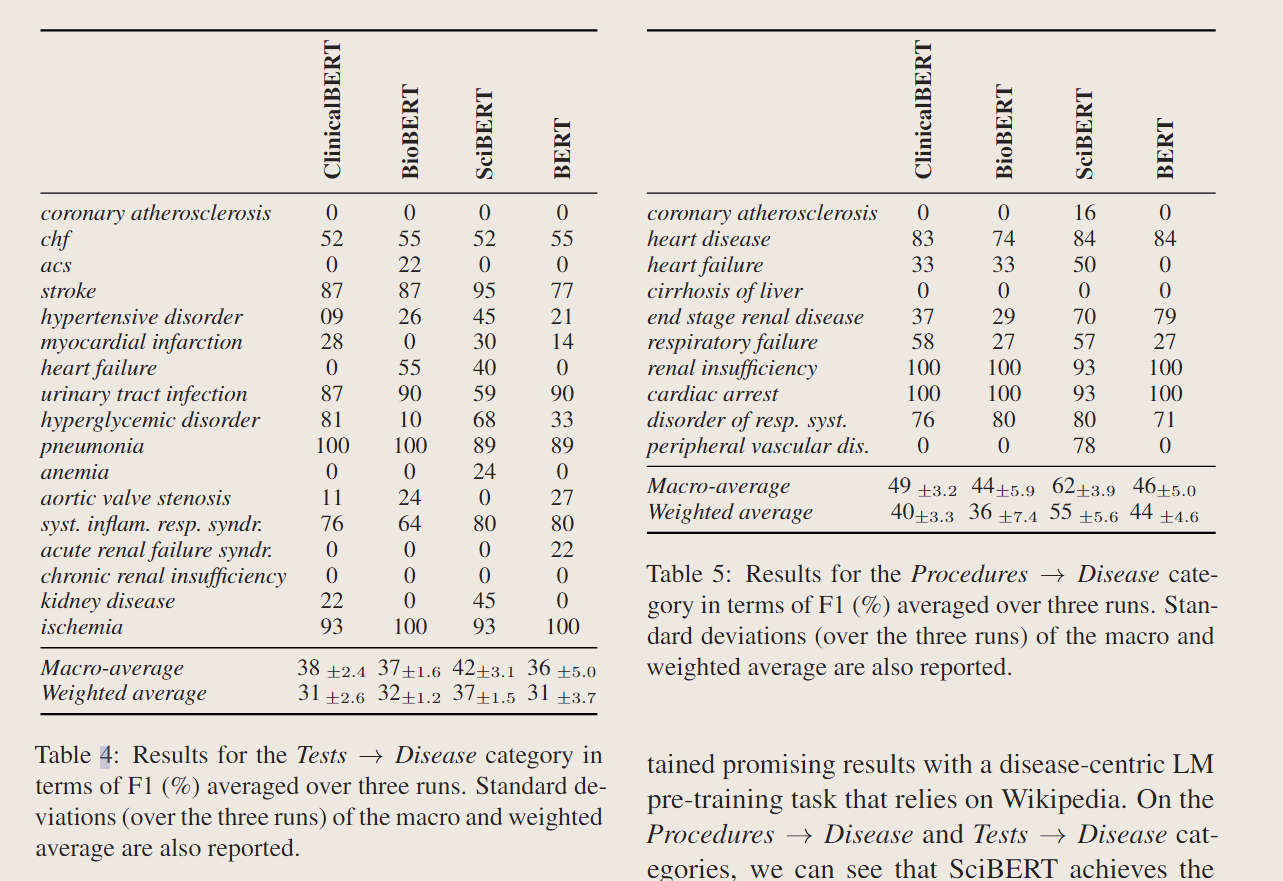
选取了一大堆预训练模型,例如BERT,BioBERT,ClinicalBERT,SciBERT,然后使用相同的超参数对于各个模型进行微调,使用十分之一的训练集作为验证划分。实验结果主要说明了,现在的预训练LMs主要在术语方面表现比较突出。特定的领域有特定的模型表现好,这里随便列举一下,就不细究了。
讨论
选哪个PLM
总得来说,每个模型都有每个模型的优缺点,SciBERT实现了最一致的性能,在部分类别都明显优于ClinicalBERT,其余类别也大体持平。而标准的BERT模型在部分领域也和BioBERT持平。
数据集的人工痕迹
发现在做最后一步规范化之前,baseline模型仍然表现很好,而在规范化之后,即使模型仅仅能访问到疾病的名称的时候仍然表现不俗,但是这没什么意义,这仅仅能表示模型相较于罕见疾病,更容易给出频繁出现的疾病。(没看懂,但是是为了说明他规范化那一步是有用的)
对抗性的实例
我们的一个产生实例的重要思想,实质上是产生最近似的疾病例子来替换掉正确的疾病实例。为了考究这一步的作用,作者使用了随即替换的方法(当然,仍然保证用作替换的Y不是X的祖先或者后代),结果表明,在随机替换之后的实验结果总体上高于之前仅选取最近似的实例。而ClinicalBERT在这种改动下受益最多。
结论
提出DisKnE作为一个新的基准,用于分析生物医学语言模型捕获疾病知识的程度。证明得到现有的医学语言模型在医学知识上的处理都遇到很多困难,但是不同的生物医学LMs具有互补优势。
Metaphors in Pre-Trained Language Models: Probing and Generalization Across Datasets and Languages
这里的隐喻感觉是指Lucky Dog相较于幸运儿这种感觉,也就是各个语言当中的黑话。
摘要
人类语言中充满了隐喻表达。隐喻通过将新概念和领域与更熟悉的概念和领域联系起来,帮助人们理解世界。因此,假设大型预训练语言模型(PLM)编码对NLP系统有用的隐喻知识。在本文中,我们通过探索PLM编码中的隐喻信息,并通过测量这些信息的跨语言和跨数据集泛化,来研究PLM的这一假设。我们在多个隐喻检测数据集和四种语言(即英语、西班牙语、俄语和波斯语)中进行了研究。我们的大量实验表明,PLM中的语境表征确实编码隐喻知识,并且大多在其中间层。这些知识可以在语言和数据集之间转移,特别是当注释在训练和测试集之间一致时。我们的发现为认知科学家和NLP科学家提供了有益的见解。
引言
首先说明了预训练语言模型是十分重要的,而且在所有的NLP应用当中都占据重要位置。
随后说明了隐喻是什么,在概念隐喻理论当中(conceptual metaphor theory, CMT)当中,隐喻被定义为将两种不同的概念或领域关联起来的认知现象。表明,建模隐喻对于构建能够将新兴概念与更熟悉的概念联系起来的类人计算系统至关重要(怪怪的表述,感觉他这里的隐喻和我们的理解不一样)。
阐述了本文的目标是验证可推广的隐喻知识是否被编码到PLM当中。
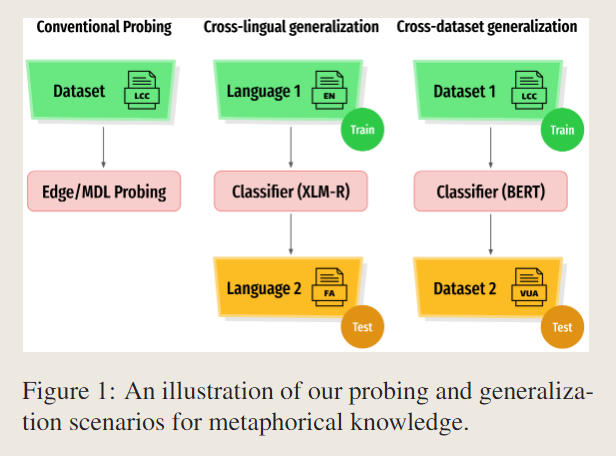
作者做的实验主要回答了以下问题:
- 不同的PLM编码隐喻知识的准确性和可提取性如何?
- PLM多层表示的隐喻知识有多深?(感觉深度这个词有点奇怪,不是很清楚为什么这么说)
为了更好的估计隐喻知识的泛化性质,设计了跨四种语言和四个不同的数据集当中的实验。
本文的主要贡献如下所示:
- 确认了PLM学到了一些隐喻知识
- 发现隐喻知识在中间层当中被编码的更好
- 在不同语言当中,具有一致的数据注释的对具有很大的可转移性
相关工作
与隐喻检测相关的工作
很多工作都去做语言当中的隐喻检测了,但是只有这个文章是第一篇跨语言的隐喻检测,使用多语言PLMs,我们执行zero-shot的跨语言的隐喻检测。(说人话的话,我觉得就是做了一些prompt直接去问预训练模型了)

NLP当中的隐喻检测方法
本文主要使用了MDL检测和边缘检测两种方法。
多语言当中的隐喻检测
很多工作都做了多语言当中的有关内容的检测工作,本文探讨了XLM-R的隐喻知识的泛化,这是著名的多语言的PLM。
分布外泛化
在隐喻检测当中研究或者评估分布外泛化方面没有早期的工作,这种泛化是指研究或者评估分布外泛化方面没有前期工作。这里的意思是测试集和训练集当中来自不同的分布,这里我们存在测试集和训练集分布在不同语言或数据集当中的场景,这是泛化编码信息的挑战性评估场景。
在PLMs当中检查隐喻知识
首先解释了隐喻的含义,说明隐喻主要使用隐喻识别过程(Metaphor Identification Procedure, MIP)进行标注。大体上的方法是寻找一句话当中的元素之间的映射关系,寻找文本当中的候选词,并基于人类的判断方法,判断每个候选是否被用作比喻表达式,并探索比喻元素之间的隐喻联系和转移方向等。这里当中也用到了概念隐喻理论(Conceptual Metaphor Theory, CMT),所谓CMT的概念,也就是说我们可以使用一个源域来解释目标域,源域往往具体而目标域往往抽象。
遵循这样的想法,在设计隐喻检测的过程当中,为了在上下文判断一个标记是否是隐喻,我们遵循下面的流程:
- 寻找token在不同的领域是否有不同的含义
- 查找目标token的源域是否与目标域当中形成对比,源域是字面意思,并不是一个上下文属性,而目标域则更依赖于上下文线索
在这里,应用这些知识,我们在预训练语言模型当中的不同层都测试了是否编码了隐喻知识,这样的跨层的test方法使我们直观的了解了隐喻的编码方式,以及隐喻的局部性和上下文关系。总结一下,做的工作主要包括如下方面:
- 调查了PLM当中的隐喻知识,分层调查
- 测试了隐喻知识当中是否可以跨语言传递,以及多语言PLM能否捕捉到这一点
- 研究了跨数据集隐喻知识的泛化,以查看不同数据集遵循的理论和注释是否一致,以及PLM学习到的是否是可泛化的知识而不是数据集当中的人工痕迹
探测
在这里,作者想要做的工作仅仅是回答PLMs当中是否含有隐喻信息这个问题,以及如果是的话,它是如何在多层的语言模型当中的各个层级之间分布的。在试图回答这个问题的时候,冻结了PLM的参数,并在顶部训练分类器来关注自身。
由于隐喻更多的依赖于源域和目标域当中的对比度检测,由于同时需要字面意思和上下文的信息,作者认为中间层当中隐喻的信息更丰富。
对于检测的具体方法,正如前文所说的,这里主要使用了边缘检测和MDL检测。
- 边缘检测:使用一个分类器,从PLM当中获得的词嵌入首先投影到256维向量后作为输入,利用这个词向量,我们可以学习到特定语言知识的编码程度。
- MDL检测:MDL即Minimum Description Length,基于信息论,简单来说是学习数据当中的异常值,复杂来说我也不懂。
总得来说,用了两种方法分别是边缘检测和MDL检测,虽然文章本身都没讲清楚。
跨语言
考察了在语言S当中学到的隐喻在语言T中会发生什么。
跨数据集
由于注释的问题以及人工痕迹的问题,我们往往会高估PLMs在做困难任务时的能力,因此,除了跨语言的传输,我们还需要考虑跨数据集之间的信息传输。即我们在数据集S上进行训练,并在数据集T上进行测试,这样可以考察在不同领域以及不同的人的标注下,模型对于隐喻检测任务的完成效果如何。
在本文所选用的四个数据集当中,不同数据集的侧重是不一样的。而且每个数据集的注释过程不同,但是我们仍然期望跨数据集之间有一定的可转移性。(通过各种角度来刁难模型)
实验
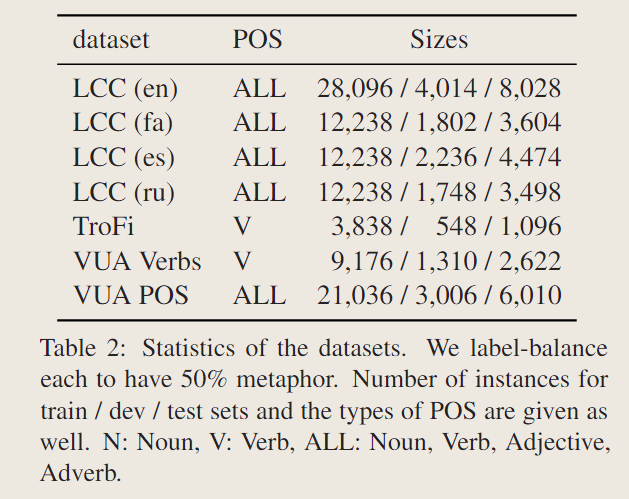
数据集
选了四个。
- LCC:爬了网络上的数据和新闻语料库,提供了隐喻分数,0(完全不是隐喻)~3(清晰的隐喻)
- TroFi:只针对动词
- VUA:分为只有动词的版本和所有词的版本
结果
选用了3个baselines,BERT,RoBERTa,ELECTRA。
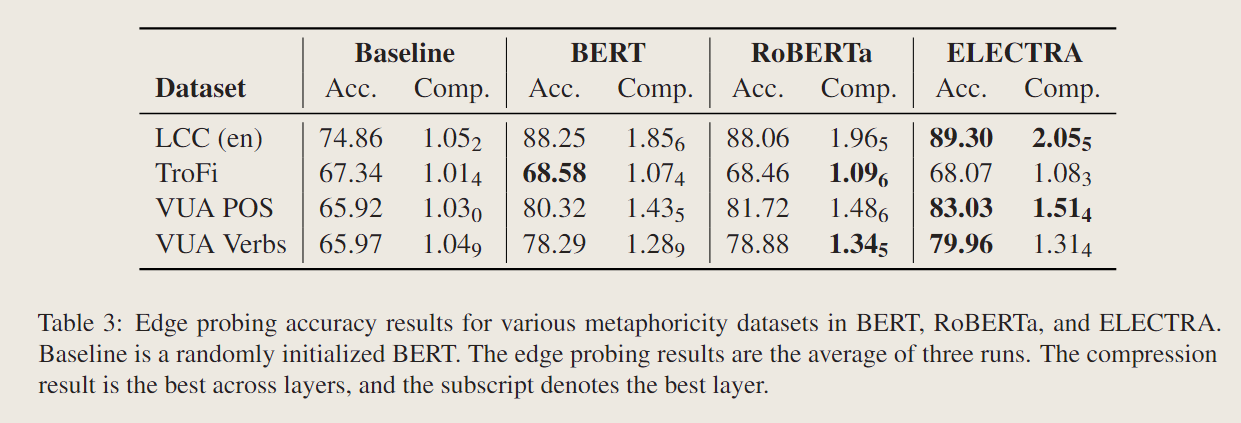
还有一个MDL的检测,证明了确实中间的隐喻含量多一点。但是他这些指标具体是怎么搞的我都不是很确定。
在泛化性方面,针对跨语言和跨数据集都做了一定的实验。
讨论
结果表明,PLM当中有隐喻,此外,跨语言很有效,但是跨数据集结果就那样。也说明了多层对于隐喻的含量是不一样的。
GEOMLAMA: Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
应该是重点文章,稍微仔细点看看。
摘要
我们首先知道,预训练模型是能够学到知识的,然而对于跨不同区域的常识知识可能会有所不同。例如,在美国婚礼上,新娘的礼服颜色是白色的,而在中国婚礼上是红色的。本文引入了一个基准数据集Geodiversity Commonsense Multilingual Language Models Analysis(GEOMLAMA),用于探索多语言PLM中关系知识的多样性。
GEOMLAMA包含3125个英语、汉语、印地语、波斯语和斯瓦希里语提示,广泛涵盖了来自美国、中国、印度、伊朗和肯尼亚文化的人所共有的概念。本文用11个PLM的baselines在这个数据集上进行了测试。有趣的是,我们发现:
- (1) 较大的多语言PLM不一定比较小的PLM存储更多地理多样性的概念(这里的地理多样性我认为实际上是指文化的多样性);
- (2) 多语言模型实际上并不偏向西方国家例如美国的知识;
- (3) 抽象的是,一个国家的母语可能不是探索其知识的最佳语言;
- (4) 一种语言可能比其母语更好地探索非母语国家的知识。
引言
和前面的论文差不多的,先夸PLM牛啊,什么都能做,然后提出自己的trouble的地方。本文主要的观点在于,由于文化和地域差异,一个地方的文化常识知识可能不能被很好的应用于另外一个地方的文化常识上,这可能会导致某些地区的用户处于“劣势”,并进一步放大人工智能应用当中的偏见,例如最终构建的数据库可能是以西方为中心的。
本文致力于评估多语言PLMs,由于不同的地区的人会使用不同的语言,给出假设是特定的地理知识在其母语当中表现得更好。经过多语言语料库的预训练,多语言的PLMs当中的知识可能会比用单一语言训练的模型中的知识更为多样。
以多语言PLM为中心,我们引入了文化多样性新的地理多样性探测基准GEOMLAMA(大概是 Geodiversity on Multilingual LAnguage Models)。而GEOMLAMA的特点总结如下所示:
- 各国的答案各不相同,每个提示都基于地域文化差异;
- 地域文化多样性概念广泛覆盖了各个主题,包括习惯,个人选择,文化和习俗;
- 覆盖了多个国家的语言,GEOMLAMA涉及美国,中国,印度,伊朗和肯尼亚的知识,由五个国家的母语(英语,汉语,印地语,波斯语和斯瓦西里语)构成。
选取了很多种基线来进行深入的探索性分析,观察到多语言PLMs显著优于随机猜测,表明多语言PLMs能够在一定程度上存储地理多样性知识,随后,本文在三个维度上进行了细粒度的调查。
- 首先是研究模型性能和模型大小之间的相关性,本文发现最大的模型不一定在我们的基准上具有最佳性能;
- 学习了能够探索特定国家知识的最好语言,以及特定语言能够探索的最准确的知识,本文发现最好的语言不是特定国家的母语,最准确的探索知识也不是关于语言的土著国家的知识(离例如,英语不是探索美国知识的最佳语言,中文提示提供最准确预测的国家也并不总是中国)