DiffuSeq, Sequence to Sequence Text Generation with Diffusion Models
原文链接:DiffuSeq, Sequence to Sequence Text Generation with Diffusion Models
再不好好看论文就要被chatGPT杀掉了.png
Abstract
扩散模型渐渐成为了生成模型当中的一种新的范式,尽管成功目前看来仅仅体现在连续域上,例如音频或者视频方面,但是我们给出了DiffuSeq——来尝试解决Seq2Seq的文本生成任务的扩散模型。通过对这个模型的一系列评估,我们发现其与目前的baseline持平,甚至表现更好,这其中也包括一个基于预训练的SOTA模型。除了生成文本的质量上,DiffuSeq的一个有趣的特性是它在生成的过程当中的高度多样性(依比不过chatGPT的fwljl看来,大概是长远的扩散步骤,提供了向其中加入一些trick来改变生成文本的导向的方法)。本文的贡献还进一步揭示了DiffuSeq与自回归/非自回归模型之间联系的理论分析。结合理论分析和经验依据,我们展示了扩散模型在复杂条件语言生成任务中的巨大潜力。
Introduction
现有的生成模型,比如GAN,VAE以及流模型都存在不稳定问题,容易发生模式崩溃,比如依赖替代目标来近似最大似然训练(虽然没完全懂,但是反正是看出来了存在一些问题x)。但是扩散模型和这些模型相比,其比较与众不同的模型结构似乎绕过了这些限制,成为了新的范式,但是将扩散模型应用于离散文本领域仍然是一个开放的挑战。
在连续域的无条件生成的基础上,大家纷纷也开始在离散域的无条件生成上做文章(即自由文本生成),为离散中的文本定制扩散模型。比如Diffusion-LM在连续空间对文本进行建模(这里指的应该是添加了EMB和Rounding方法),并建立一个分类器来引导文本生成。但是对于Seq2Seq问题而言,我们给出的分类器的条件也是一个单词序列,产生的也是一个单词序列,我们无法训练无数个分类器来建模条件和生成的语义之间的关系。
Seq2Seq文本生成是自然语言处理当中一个重要的话题,涵盖了许多重要的任务,比如开放式文本生成,对话,机器翻译以及文本风格迁移。在本文当中我们提出了DiffuSeq,一种支持Seq2Seq文本生成的无分类器扩散模型。相较于Diffusion-LM来说,DiffuSeq的一个优点在于,其不依赖于特定的分类器,而是允许一个完整的模型来拟合数据分布。
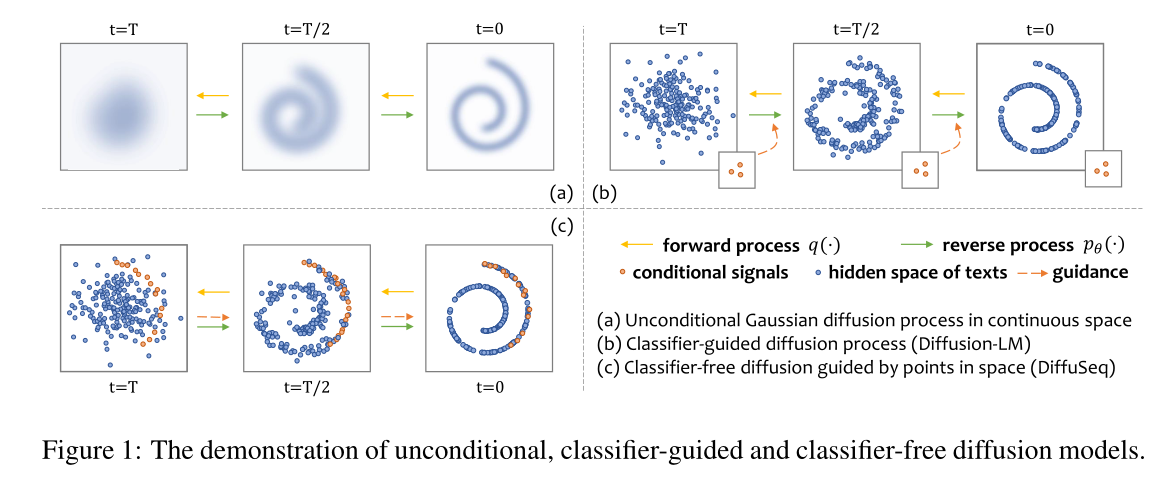
上图中比较清楚的看出了这几种生成的范式,例如(a)部分表示连续域上无条件的生成,(b)部分类似Diffusion-LM的方法,通过分类器来无形当中引导文本生成,(c)部分就比较简单粗暴,直接把原文也丢进去,一起生成,去噪和加噪都只针对其中的部分信息进行。
为了证实DiffuSeq模型的有效性,我们对四个Seq2Seq任务进行了实验,与自回归以及非自回归模型相比,DiffuSeq可以在不牺牲句子的质量的情况下有较多的多样性,同时,自回归和非自回归模型存在退化问题,而且依赖解码的策略。
综上所述,我们在技术上和理论上都做出了一系列的贡献:(a)我们是第一个将Diffusion Model应用于Seq2Seq的团队,我们提出了DiffuSeq作为条件语言模型,以一种无分类器的方式进行端到端的训练;(b)我们建立了自回归,非自回归模型以及DiffuSeq模型之间的理论联系,并且证明了DiffuSeq模型是迭代-非自回归模型的一种扩散;(c)有了强而有力的经验证据,我们证明了扩散模型在复杂条件语言生成当中有巨大的潜力。
Preliminary and Problem Statement
序言
扩散模型包括正向反向过程,给定一个从某个分布(一般来说是高斯分布)当中采样的数据,我们在训练过程中通过正向加噪来将原始数据逐步腐蚀为高斯噪声,也可以在反向的解码过程当中,通过逐步去噪来试图重建原始数据。
问题陈述
近年来,很多工作都效力于使扩散模型适应于离散的文本,然而这些工作大部分都关注了无条件的序列建模。在本文中,我们的目标是Seq2Seq的文本生成任务:给出一个源序列$w^x={w_1^x,…,w_m^x}$,我们旨在学习一个扩散模型,其可以产生一个目标序列$w^y={w_1^y,…,w_n^y}$
DiffuSEQ
我们在本文当中提出DiffuSeq来扩展普通的扩散模型,从而学习条件文本生成。下文的内容涉及到模型架构和训练目标。
Forward Process with Partially Noising
在前向过程(扩散过程)开始的时候,我们遵循Diffusion-LM的方法设计了一个EMB函数,从而将离散文本w映射到连续空间当中。特别的,对于模型接下来的计算,这里定义一个新说明。对于一对给定的序列$w^x,w^y$,DiffuSeq通过变化和拼接学习到两者的一个统一特征空间,我们给出$EMB(w^{x\oplus{y}})=[EMB(w_1^x),…,EMB(w_m^x),EMB(w_1^y),…,EMB(w_m^y)]\in\mathbb{R}^{(m+n)\times{d}}$。通过这样的方法,我们可以将原始的正向链扩展到新的马尔可夫过程当中,从而使得离散文本的输入可以适应于标准的正向过程。
相较于Diffusion-LM,本文的不同点在于,模型给出了$z_t=x_t\oplus{y_t}$,其中$x_t,y_t$分别代表$z_t$当中属于$w_x,w_y$的部分(即一个是输入的seq,一个是将要输出的seq)。我们将$z_t$作为每步扩散当中优化的对象。和传统的Diffusion Mode,包括Diffusion-LM不同的是,本文当中对于正向的扩散加噪过程,我们只对$y_t$施加噪声。这种修改(称为部分噪声)允许我们使用条件语言模型去建模扩散模型。在实现方面,我们采用一个anchoring function(也许可以翻译为锚定函数),来每次使用原始的$x_0$替换掉被污染的$x_t$。
Reverse Process with Conditional Denoising
反向过程的最终目的是通过去噪$z_t$来重建$z_0$,其实和前面的过程是类似的,这里需要注意的是,由于之前正向的加噪过程中没有使用分类器,而是将$x_t,y_t$直接拼接起来,我们不需要额外训练的分类器来控制去噪过程。
特别的,我们使用一个transformer来建模$f_{\theta}$,个人认为是:$f_{\theta}(z_t,t)$。而他会自发的建模$x_t$和$y_t$之间的关系,通过原先的计算过程计算变分下界。
本文的损失函数被优化为如下所示:

在这个过程当中,我们使用$\tilde{f_\theta}(z_t,t)$来表示恢复的$z_0$对于$y_0$的部分。需要注意的是,尽管我们在损失函数当中的第一项仅仅计算了有关$y_0$的部分,但是由于transformer当中的自注意力机制,$y_0$的重构同样考虑了$x_0$,因此来自第一项的梯度也受到$x_0$的影响。
值得说明的是,作者认为自己同时对$x_t,y_t$进行训练,实现了两个不同特征空间的联合训练,这使得DiffuSEQ和现有的解决方案不太一样。
Connections to AR, Iter-NAR, and Fully-NAR Models
作者认为,DiffuSeq模型相当于迭代式的非自回归模型一种扩展,作者在本节给出了自回归(AR),迭代非自回归(iter-NAR)和完全非自回归(full-NAR)模型的理论联系。
在讨论三者之间的理论联系的时候,作者使用了条件序列生成的例子进行举例。所谓条件生成模型,其目的是学习$w_x,w_y$的条件概率$p(w_{1:n}^y\mid{w^x})$。
对于AR模型,其通过自回归的计算来累乘多个条件概率,如下所示
\[p_{AR}(w_{1:n}^y\mid{w^x})=p(w_1^y\mid{w^x})\prod_{i=1,...,n-1}p(w_{i+1}^y\mid{w_{1:i}^y,w^x})\]对于full-NAR模型,通过学习给定的独立假设的条件概率进行快速推断
\[p_{fully-NAR}(w_{1:n}^y\mid{w^x})=\prod_{i=1,...,n}p(w_i^y\mid{w^x})\]这里,作者给出了(或者是本来就有,但是我不知道)一个iter-NAR模型的定义,即迭代式的非自回归模型,迭代式的非自回归模型给出了一种无损的结合非自回归模型和自回归模型的方法,给出了下列公式
\[p_{iter-NAR}(w_{1:n}^y\mid{w^x})=\sum_{w_1^y,...,w_{K-1}^y}\prod_{i=1,...,n}p(w_{1,i}^y\mid{w^x})\prod_{k=1...K-1}\prod_{i=1...n}p(w_{k+1,i}^y\mid{w_{k,1:n}^y},w^x)\]
作者指出,在AR模型与NAR模型之间效果(这里应当是指正确率方面)存在明显差异的原因在于,NAR在AR的基础上做了有损的分解。然而在iter-NAR面前,其可以像AR模型一样被因式分解为初始的概率值,以及可回归的全文的预测。因此有工作指出,其在较大的迭代次数下可以与AR模型的效果更接近(哈哈,我不信)。
这里给出一些自己的理解,对于AR模型来说,我们的语言模型描述的是给出第一个字符,我们根据第一个字符递归的产生第二个字符,以此类推;而对于iter-NAR模型来说,我们实际上是根据第一轮的$w^y$来递归的产生直至第K-1轮$w^y$,随后我们将产生的这K-1轮$w^y$都应用起来。
我将再用一段来痛骂这个公式的符号表示太不清楚,以下的说明均来自于我自己的猜想,如果说错了我将不负任何责任:$\sum$在此仅表示,我们会将K-1轮产生的结果联合应用起来;$w_{m,n}^y$表示第m轮的$w_y$当中的第$n$个字符。总的来说就是我们递归的产生了K-1轮结果。
然后,作者说明了DiffuSeq也是一个iter-NAR的结构形式,这里作者是这么说明的,我懒得敲公式了,直接贴一张图上来:

我个人是这样理解这个公式的。我们可以看到,左边$\sum$的部分表示我们联合使用了从$T\to{1}$的扩散步骤,右边累乘的第一项因子表示,我们已知向量和$w^x$来clamping出来的$w^y$,第二项则表示我们根据clamping出来的$w^y$向前重建,推导出下一步。
Training and Inference Methods
作者还采用了一些训练和推理的技巧,比如重要性抽样,最小贝叶斯风险编码,但是我都不甚了解,就先暂且搁置一下。
至此,我们已经将模型的结构部分大概说明清楚了,实验部分先略过!