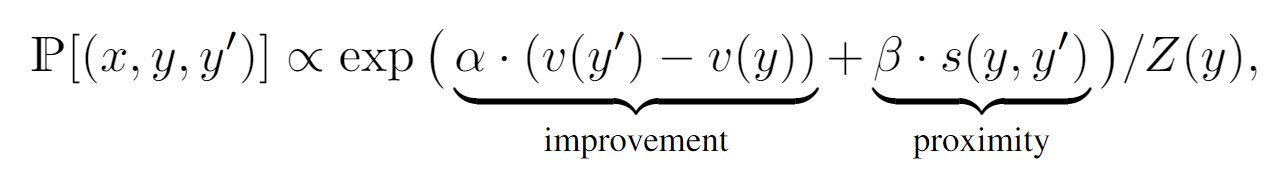GPT类的大模型的QA问答相关文献整理
写在前面
最近身边有很多人都毕业了,自升学以来,我常常都会有孤独的感觉,除了47,我的大部分,或者说几乎所有的本科的朋友都已经不在同济了,虽然现在的生活也不能说不好,无论是宿舍还是实验室还是课题组的氛围。但是在逛超市的时候总是能想到当初封校的前一天,宿舍一起在小卖铺搬成箱的冰红茶,补办的毕业典礼我也没有去,因为没有什么值得合照的机会,看到大家的合照又会想起宿舍分别的前一天晚上。之前的生活常有不开心,但是回到宿舍和大家一起蹉跎岁月总是开心的,果然还是想念本科的时光呀。

GENERATING SEQUENCES BYLEARNING TO [SELF-]CORRECT
摘要
本篇文章主要关注了序列生成的问题,重点提到了:当前的生成方法中缺少迭代修改输出的机制 。提到迭代修改输出,更多的会联想到例如PPLM这种后处理的技巧,不过针对非常强大的LLM来说,由于其参数量很夸张,或者类似chatGPT这样无法访问,那么就不能通过更新参数来适用于不同的任务。因此,比较容易想到的方法就是直接利用生成的结果来适用于特定的任务。
本文提出了SELF-CORSECTION,将不完美的基本生成器与学习迭代不完美代的矫正器解耦开来,通过单独训练校正器,来提升效果。当然,为了训练校正器,本文也提出了在线训练程序,可以在中间的不完美代上应用标量或者自然语言反馈(感觉和openAI那一篇很像,可能就是为人类专家提供了一种标注方法)。
与此同时,本文表明了自我校正在三种不同的生成任务(数学程序生成,词法约束生成以及毒性控制)当中对基本的生成器都有提升,即使校正器比基本生成器小得多。
引言
指出,生成模型不会利用失败的生成序列,也就是说,生成次优的序列中,按照单遍生成的范式,在尝试重新生成正确的序列的时候,也会完全丢弃掉之前的工作,更自然的方法是利用有用的起点来细化更高质量的输出。
有了motivation就会有method,形式化的方法是引入了这种序列生成的自校正。
个人觉得这个图画的比较简略,很粗犷,第一阶段是生成器,然后通过不知名的方法去修改优化生成器产生的结果,再去产生更好的结果,但是这里看到,他的优化方法很像是人标的,我觉得可能就是使用在线的训练平台提供了标注数据的方法。不过这里特别提到了可以将任务分解为多个子任务给高效的子系统。 本文指出,校正器可以迁移到其他的生成器当中,任务也可以经过训练而迁移。
自校正的序列生成器(Self-correcting Sequence Generators)
同样是提出了一个符合动机的方法后找了一个理论支撑,同样是利用贝叶斯公式。
\[p(y\mid{x})=\sum_{y_0}p_0(y_0\mid{x})p_\theta(y\mid{y_0,x})\]当然这里我没细推过这个公式,不过稍微瞄一眼能看出来大概是对的。
生成器会首先给出一个初始假设,校正器会不断地优化这个初始假设,这里当然,校正器可以迭代使用,因此这个公式也可以改写为以下的形式:
\[p(y_T\mid{x})=\sum_{y_0}\sum_{y_1}···\sum_{y_{T-1}}p_0(y_0\mid{x})\prod_t{p_\theta(y_{t+1}\mid{y_t,x})}\]同时,文中指出,这里所使用的校正器和生成器是可以拆解开来的,也就是说,他们是不太相关的两部分,可以分为两个部件,其中生成器可以直接使用大语言模型等通用的语言模型。
不过这里提到了一个部分,也是我比较关心的部分在于,校正器是需要训练的,这里提出了一个训练框架(还没看,但是感觉是手标)。
训练一个校正器(Learning a Corrector)
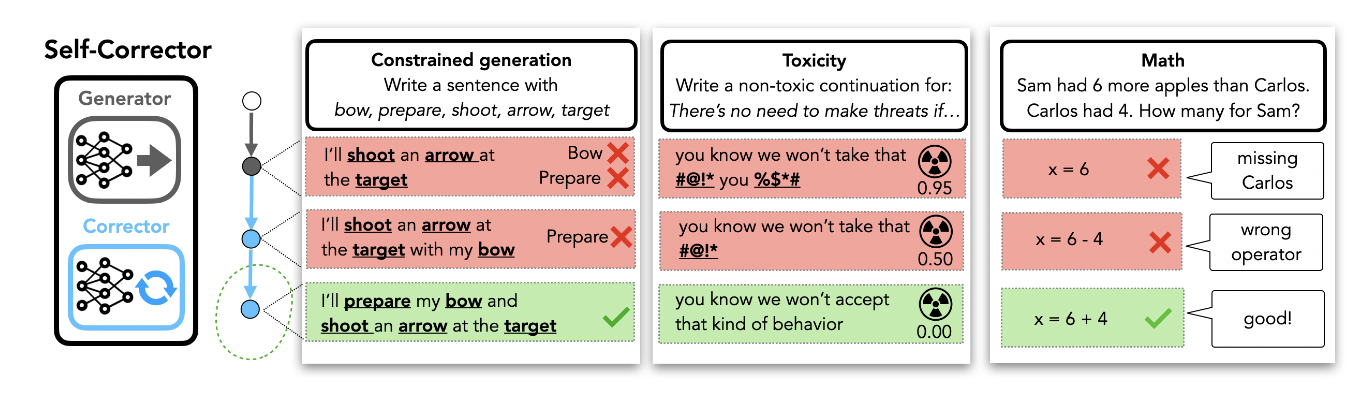
这里首先给出了一个概述图,也很符合直觉,也没什么好讲的。首先生成一个初始假设,然后校正器根据初始假设给出置信度(或者是打分,没看懂具体是啥),再迭代即可。
需要注意的是,这里针对“生成的句子当中包含关键词”这个任务,似乎是通过训练corrector,让他对超量生成的句子对做对比学习,从而能够直接根据对比学习的方法给出评分(或者置信度)。
这里没理解的地方在于,他自己编了一个词叫做value-improving pairs,很难不让人想到对比学习。
结合后面的内容,猜测这里应当是这样的,通过不断的迭代生成,产生超量的数据,同时拥有一个校正器,校正器可以通过输入直接产生一个更好地回答,可能是面向特定任务的Seq2Seq的专家系统
另外还在想,这样他这东西不是就是个相似度评估,怎么感觉不是很需要learn a corrector。这里的相似度评估应该是分类器之类的。
同样的,这里给出了一个算法的流程图。然后后面详细解说一下。

算法的各个步骤(乱序)如下所示:
- 概念假设:生成器(generator) $p_0(y_0\mid{x})$,校正器(corrector) $p_{\theta}(y’\mid{y,x})$,一组prompt $X$,人类的反馈$f:\mathcal{Y\to{F}}$
目的:学习出一个校正器,从而同时利用生成器产生的结果以及人类的反馈$p_{\theta}(y’\mid{y,x,f(y)})$
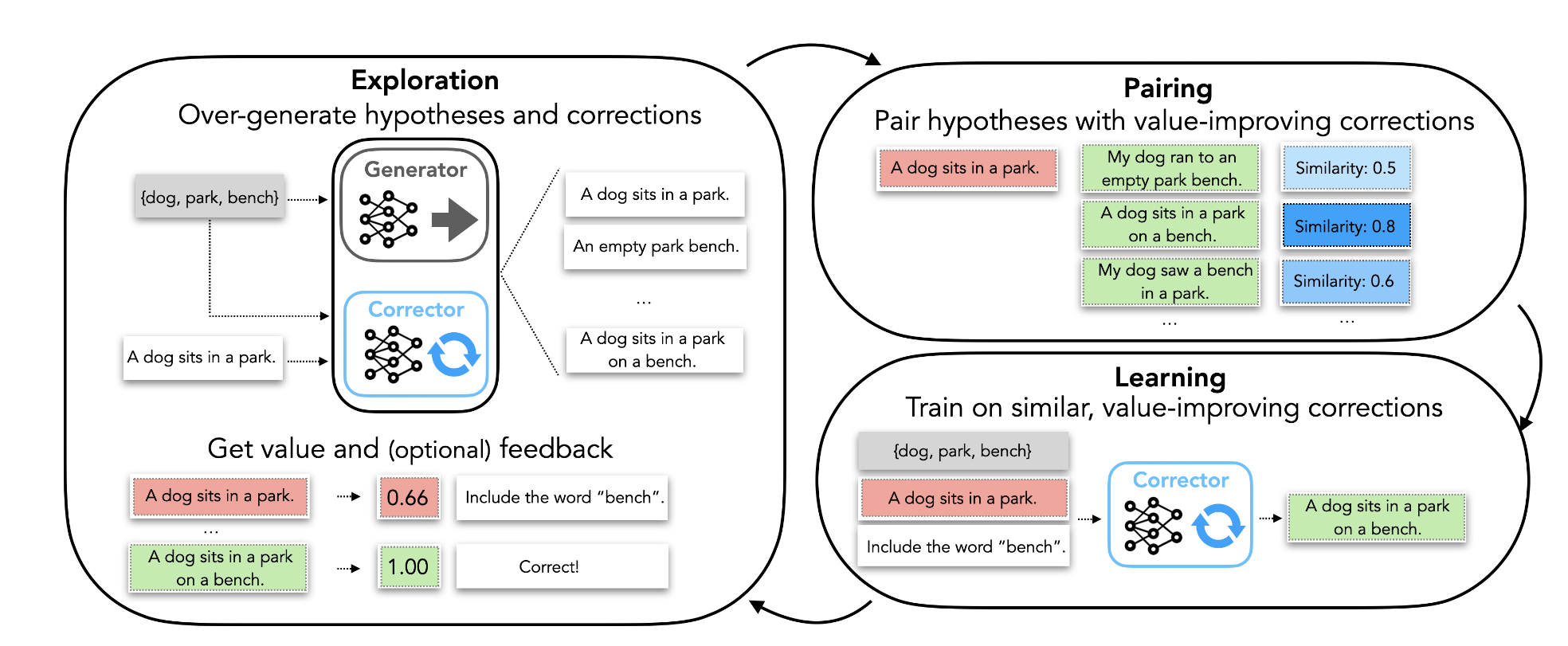
初始化:利用生成器当中产生的超量的数据构成datapool,其中的每个元素由“输入,输出,值,反馈”,形式上如下所示,设计一个这样的形式是为了后面如果有补充的数据,可以更方便的添加进来:
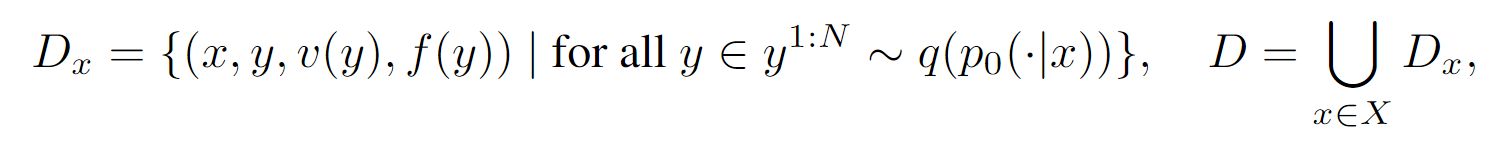
配对(Pairing):看了半天,终于明白啥是value-improving了,这里构成了一个新的集合,由“输入,假设,纠正”构成,对于假设,自然是由生成器产生,而纠正由校正器产生。
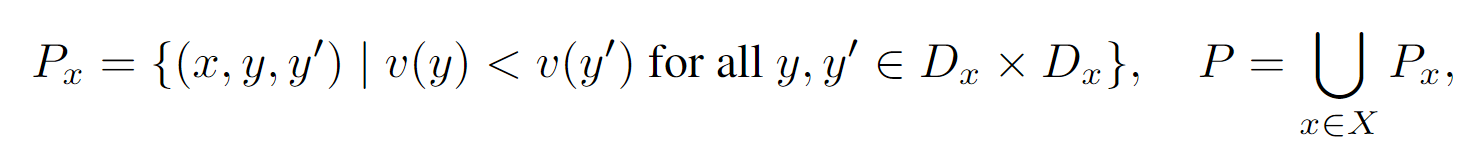
- 学习(Learning):选取配对后的部分数据来作为校正器的训练数据,具体的选取逻辑在于,根据假设和提升之间的提升程度以及相似度来选取。实际上是设置了$\alpha$和$\beta$两个超参数来辅助选取部分配对后的数据用来训练,虽然感觉没什么道理,可能是先有的实现效果。