Prefix-Tuning, Optimizing Continuous Prompts for Generation
原文链接:Prefix-Tuning: Optimizing Continuous Prompts for Generation
他人博客:
- 博客园:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- CSDN:Prefix-Tuning: Optimizing Continuous Prompts for Generation翻译
- CSDN:[文献阅读]——Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 腾讯云:No Fine-Tuning, Only Prefix-Tuning
摘要
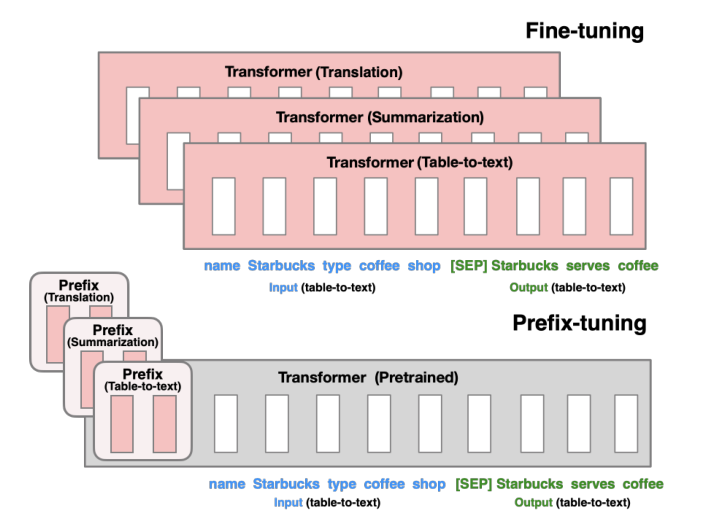
在预训练任务当中,我们常用的方法是Fine-tuning(微调),对于大规模预训练模型应用于下游任务,采用微调的方法修改所有的语言模型参数,需要为每个任务存储完整的副本(在当前大规模应用大模型的时候是比较昂贵的)。
Prefix-tuning(前缀调优),对于特定的任务优化一个连续的向量序列(continuous task-specific vector, called prefix),添加到每一层当中。
引言 & 相关工作
Adapter-tuning:在已经训练好的各个语言模型层当中插入额外的特定任务的层。
Lightweight fine-tuning:选择一些参数进行调整。
上下文学习:一种比较极限的情况,不用修改参数(但是我不懂)。
Prefix-tuning:尝试在输入层和每一个transformer层引入预先设置好的前缀,在训练的过程中frozen模型内部参数,仅仅训练前缀。
任务介绍
文中采用生成式的任务,例如table-text,summary,在其中:
- $x$表示输入,$y$表示输出(例如在table-text当中,$x$表示输入的表格,$y$表示输出的序列;在summary当中,$x$表示文章,$y$表示摘要)
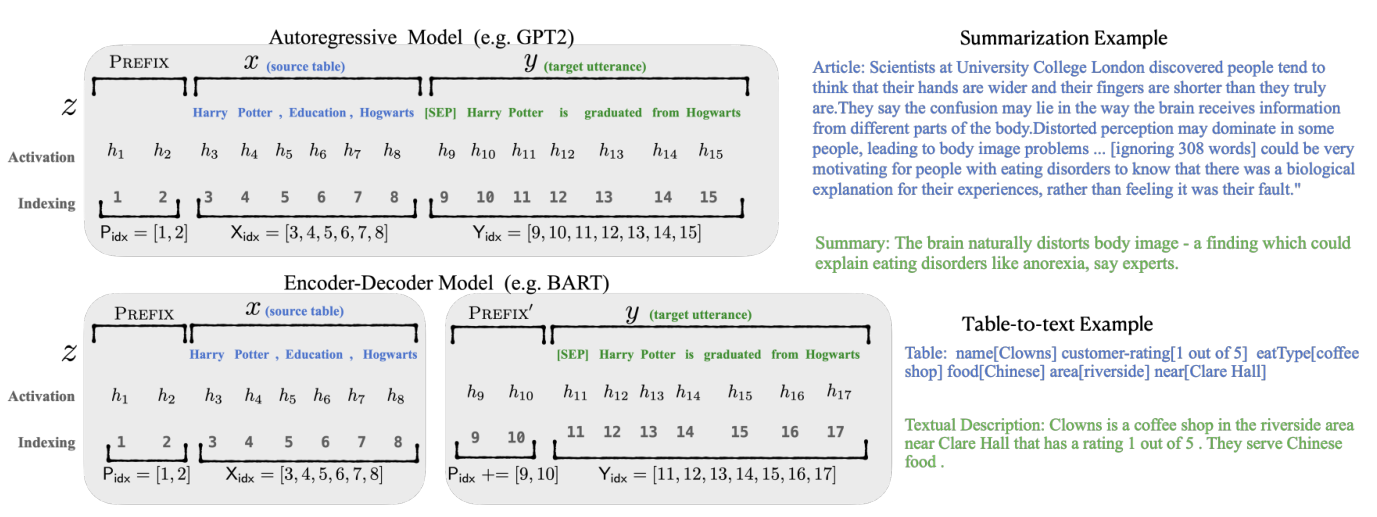
如上图所示的,对于自回归的模型和编码器-解码器的模型,prefix-tuning采用了不同的方法添加前缀。
当然这里首先描述一下两种不同的模型架构下如何对任务进行计算:
- Autoregressive LM $z=[x;y]$,x和y的拼接 $h_i^{(j)}$表示time step $i$下第$j$层transformer layer的激活层
首先计算$h_i$,$h_i=LM_{\phi}(z_i,h_{<i})$
最终计算下一个字符的概率分布,$p_{\phi}(z_{i+1}|h_{\leq{i}})=\rm softmax(W_\phi,h_i^{(n)})$,其中$W_\phi$是可训练的,将$h_i^{(n)}$映射到词汇分布的预训练矩阵
- Encoder-Decoder Architecture 其中$x$由双向编码器编码,并且用解码器自回归地去预测$y$,计算方法和自回归模型类似
倘若采用fine-tuning,对以下对数目标执行梯度更新(懒得打了QAQ):
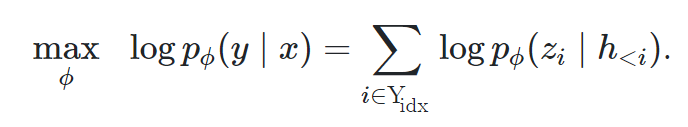
Prefix-Tuning
本文采用了Prefix-Tuning的方法来替代上文说的Fine-Tuning。
直觉
(采用了这样的标题,让我感慨什么时候我才能变成科研锦鲤,一点就中)
prompting启示我们,适当的上下文可以在不改变参数的情况下引导LM。但是通常来说,离散的“命令”可以指导专家标注,但是不能指导模型工作,因此我们可以采用连续的字符嵌入来优化,即对transformer的所有层添加一个前缀。
方法
Autoregressive LM $z=[PREFIX;x;y]$
Encoder-Decoder Architecture $z=[PREFIX;x;PREFIX’,y]$
由prefix-tuning产生的激活层计算如下所示:
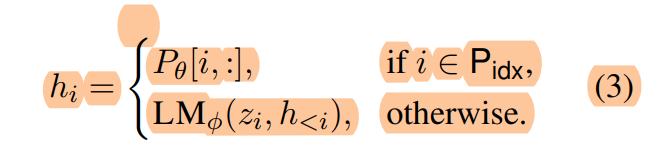
- 对于上式第一行,指在前缀序列内,直接拿着一个可训练的向量$P_\theta$与前缀相乘即可。
参数化(但是不懂)
直接去训练$P_\theta$不够稳定,性能也会下降,进行重参数化,这里摘录了一个别人的博客。

实验
略