The Power of Scale for Parameter-Efficient Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
原文链接:The Power of Scale for Parameter-Efficient Prompt Tuning
他人博客:
摘要
把Prompt作为一个可训练的向量,固定整个大型的预训练模型PLM,微调Prompt来适配下游任务
随着PLM参数规模的增大,Prompt Tuning和Fine Tuning的性能越来越接近
Prompt Tuning(或者说是基于Soft Prompt的提示微调)可以看作Prefix Tuning的简化版本
研究方法与结论
Fine-Tuning & Prompt Tuning
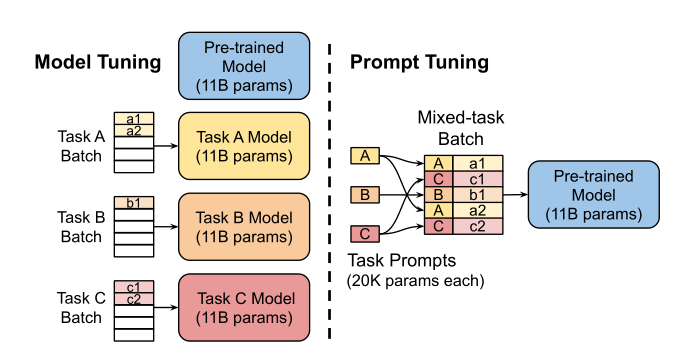
传统的微调方法需要对所有参数进行调整,针对不同的任务使用不同的微调方法,需要对于不同的任务存储不同的模型副本
提示微调,会使得对于不同的任务学习不同的提示,插入到任务的输入当中,肉眼可见的,这样的存储效率会更高,我们不需要保存较大的模型副本
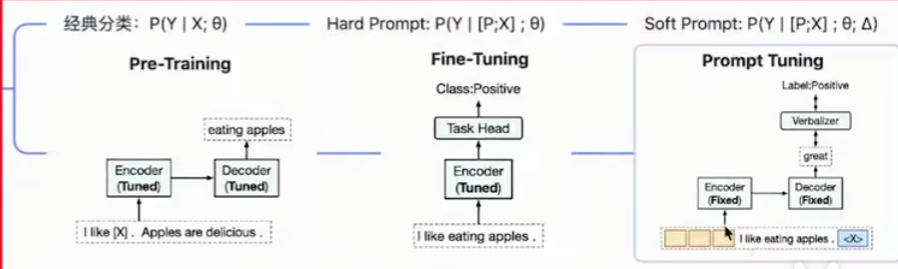
最左边的是传统方法,给定输入$X$和参数$\theta$,可以得到输出$Y$
中间的是GPT3的方法,通过给定输入$X$和一些额外的句子$P$,加上参数$\theta$,可以得到输出$Y$
最右边是基于提示微调的方法,在前文的基础上给出一些提示向量$\Delta$,得到输出$Y$
Prompt-Tuning的影响因素
模型本身的参数量(原文当中使用了从T5到T5-XXLarge的模型做实验)
使用语言模型的生成,尽力在输出目标当中消除哨兵标记(这点不是很理解,贴上一些别的博客,是和T5模型的预训练任务有关)

初始化方法
- 随机初始化
- 使用预设文本的词向量初始化,类似于设计hard prompt
- 使用类别词向量初始化,类似于提供选项
实验 & 结论
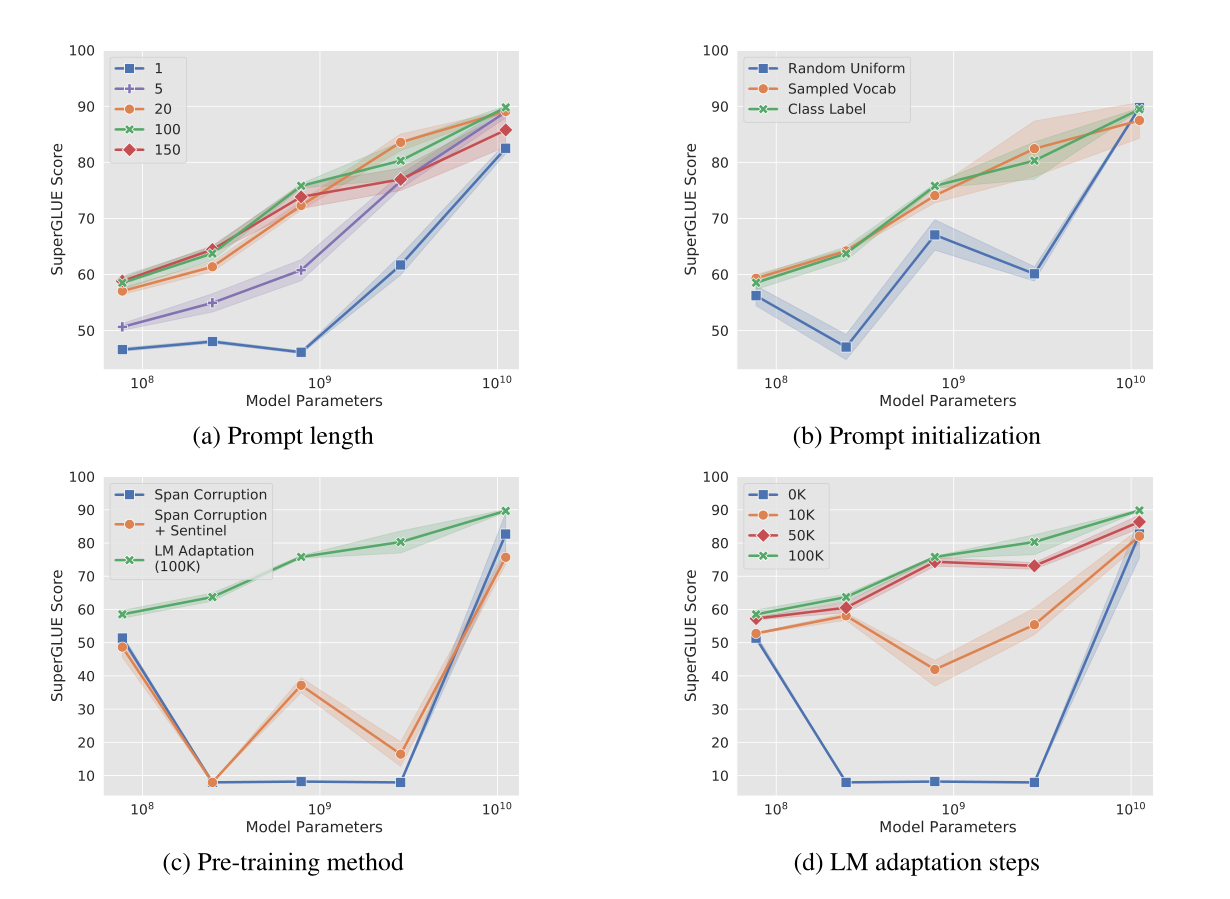
(a) Prompt的规模越大效果越好
(b) 基于语义信息的初始化比随机初始化更好
(c) LM Adaptation对性能提升很显著
(d) 模型越大,方法效果越接近
本文由作者按照 CC BY 4.0 进行授权