Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
原文链接:Disentangling Reasoning Capabilities from Language Models with Compositional Reasoning Transformers
摘要
提出了一个统一的推理框架ReasonFormer,反映人类在复杂决策当中的模块化和复合推理过程
将表征模块(representation module)和推理模块(reasoning module)分离开来
将推理的过程模块化,通过并行/级联的方法动态激活和组合不同的推理模块
总的来说,将一个推理任务分为多个部分,通过一个路由模块(skill route)来激活不同的推理模块。
引言
大模型不能模拟人类进行推理(感觉确实是一些废话)
通过一个举例来说明人们进行推理的时候一般分为两个部分,先直观的理解问题(system 1),然后进行级联的组合推理(system 2),即经过了这样一个思考过程:回忆事实$\to$逻辑演绎$\to$回答问题。
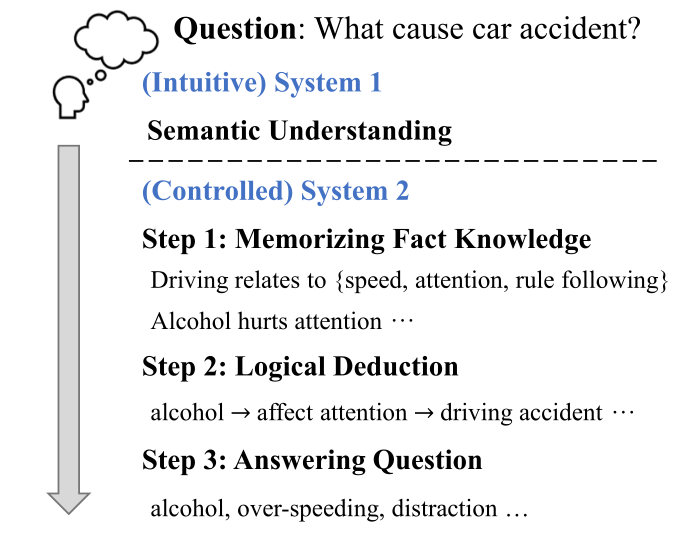
然后作者做出了一个看似很符合直觉,但是总觉得没那么有道理的假设(原文当中说基于了一个心理学的什么东西):上文所述的system 1和system 2可以解耦,且system 2当中复杂的推理过程可以分解为多个基本的推理过程,从而使得我们可以运用预训练数据来较好的分别训练不同的基本推理过程。于是,作者提出了ReasoningFormer来反映人们的复杂推理过程,具有以下的特点:
表示模块和推理模块解耦
推理模块模块化,在基本的推理技能上具有专业性
推理模块采用并行或者级联的方式组成,自动确定激活的推理技能和所需的推理深度(听学长的组会讲解说是有一个skill路由模块,虽然感觉有一点点魔幻)
整个推理框架用一个模型解决多个任务,可以seq2seq的进行训练和推理
推理能力制定
具体的来说,整个模型貌似分为下述四个模块:
表示模块:用多个transformer层来学习上下文语义和对问题的直观理解
推理模块:通过预先训练,成为特定推理技能的专家(逻辑,命名实体识别,简单QA,常识等等,ps:笨蛋专家),因为这些技能都比较笨蛋,所以可以有大量的优质预训练资源
推理路由器(reasoning router):决定使用哪些推理技能,什么时候结束推理
适配器(adapter):使得可被重用的推理模块适应推理过程的不同层次
在选取基本技能的时候,我们首先需要理解事件的关键信息,回忆相关的事实知识,理解语义相关性以及事件之间的因果关系,最终为问题提取答案。(原文当中用了extracting这个单词,但是我觉得也有可能是生成)。基于上述的原因,我们选择以下基本技能:
逻辑能力(logic)
简单问题问答(QA)
命名实体识别(NER)
自然语言推理(NLI)
general skill:在选定的技能当中学习共同的知识
模型框架
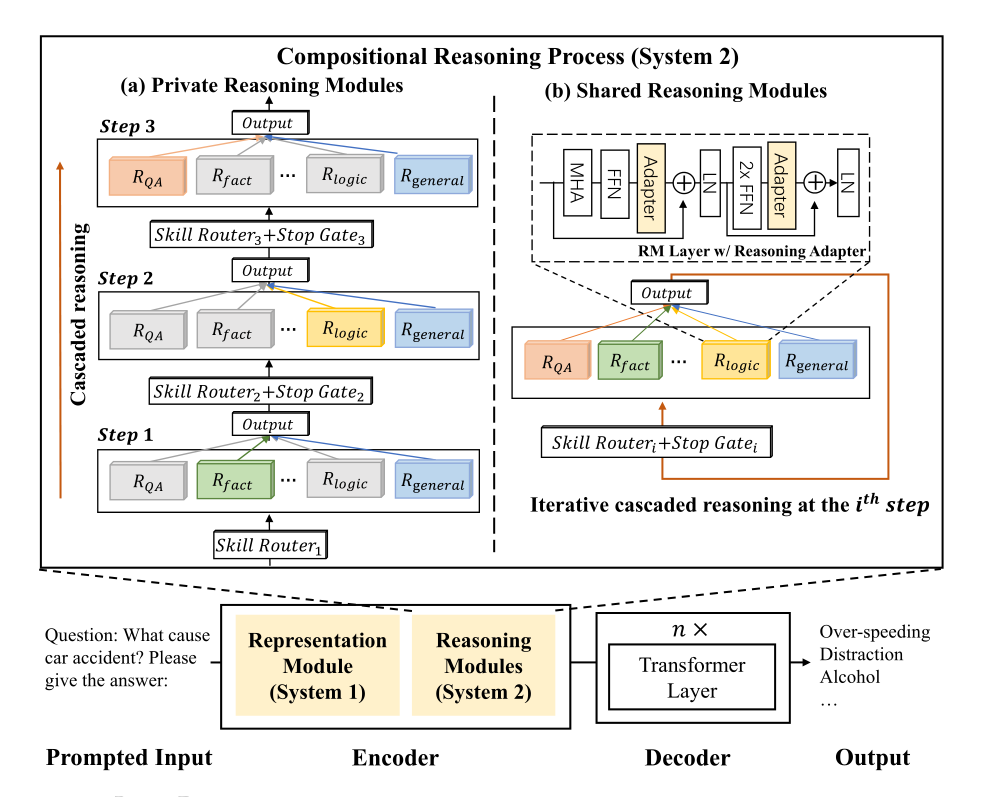
整个模型的框架如图所示,使用了encoder-decoder的结构来对不同的推理任务进行处理。需要说明的是,对于ReasonFormer,所有的任务我们都采用统一的模型进行处理,首先会将所有的任务转换为text2text的文本生成任务,使用hard prompt的方式进行格式的转换。这里其实是一个比较粗暴简单的方法,作者举了一个这样的例子:
The question is { Question }. Please give a answer:
Representation Module
基于transformer的LM展示不错的上下文的表征能力,于是我们将长度为m的表计划的输入X输入到模型当中,表示模块当中我们学到的初始表示是:
\[H^0=\{h^0_{[CLS]},h^0_1,h^0_2,...,h^0_m\}\]总结一下,作者把输入直接丢进一堆transformer层当中,然后觉得没有什么好讲的了。
Reasoning Module
对于推理模块,采用模块化和组合的方式,推理模块学习在预训练当中指定的不同推理技能,并在下游与adapter和reasoning router自动组合。这里需要说明的是,对于推理模块,其不仅仅在并行层面上有组合性,在级联层面上由于多步推理的存在,也有相关组合性。
对于同一推理技能在不同的步骤的共享或私有主模块参数,文章当中提出了两种推理模块(虽然感觉分类的很草率,但是看在他后面讲解了,还是简单看看8):
共享推理模块(shared reasoning modules)
私有推理模块(private reasoning modules)
以上的每个模块都由若干个transformer层组成(不知道包不包括下面的)。
当然,整个RM当中还包括一些其他部分:
reasoning router
pre-training and adapter
Reasoning Router
对于每个实例,所需要的能力和推理深度是不同的,因此,我们需要推理路由器决定每个推理步骤需要激活哪些技能。在并行层,技能路由器(skill router)计算每个推理步骤当中推理模块的激活分数。在每个推理步骤之后,停止门(stop gate)决定执行的推理步骤是否足以解决问题。
Skill Router
对于第i个推理步骤当中的n个推理模块:$R^1,…,R^n$和一个技能路由器$S^i$,我们可以通过路由器加权的n个推理模块的平均输出$H^i$来计算第i个推理步骤的输出。
\[H^i=\sum_{j=1}^{k}S^i(\hat{H}^{i-1})_jR_j(H^{i-1})\]其中右边的两个因式分别来自于路由器和第j个推理模块的输出。
决定每个步骤的推理技能是一项非平凡的任务,我们采用了一个相对复杂的路由器来进行更深入的理解。我们首先使用一个Transformer层T来将原始输出做映射:
\[\hat{H}^{i-1}=T(H^{i-1})\]最后,我们再使用FFN(前馈神经网络)和Softmax函数进行加权评分计算:
\[S^i(\hat{H}^{i-1})=Softmax(FFN(\hat{H}^{i-1}))\]Stop Gate
在每一个推理步骤结束后,停止门决定当前推理深度能否足以解决问题,使用第i个推理层的输出$H^i$作为输入,使用残量门控机制来控制所执行步骤的信息流。(不懂)
\[\tilde{H}^i=H^{i-1}+G^i_{stop}(H^i)\]我们使用FFN层作为停止门,当推理过程足够充分的时候,使用停止门计算较小的权重来软停后续过程。
Shared Reasoning Modules
如最上面的模型图所示,不同推理深度,对于相同的推理技能来说,具有共同的共享参数。最后一个推理步骤的输出将会在特定步骤的adapter下递归的重用于特定的推理模块的输入。
有关Reasoning Adapter,为了使重用的推理模块适应推理过程的不同深度,我们在推理过程中添加了特定于步骤的推理adapter。而对于不同技能和不同推理深度的adapter是非共享的。
Private Reasoning Modules
与共享推理模块不同的是,由于私有的推理模块在不同推理深度的模块参数是非共享的,因此不需要使用adapter,如图2所示,私有推理模块级联,前一步推理的输出直接作为下一步推理的输入。