A Survey of CTG
参考文章:A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
写在前面的前面
新年快乐,这段时间需要加油啦!
可控文本生成是现在产生的一个比较新颖的方向,其主要的建模目标在于,将我们给出的条件或者称之为属性放入我们的输入当中,从而建模$P(Y\mid{X,c})$这样一个目标,最终使得我们的输出可以在给定的输入和属性下产生我们想要的,具有属性c的文本内容。
笔者注意到,大部分网络上整理的内容都是完全基于A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models(后面简称Survey)这篇综述文章的。
诚然,这篇文章的确是CTG的有关内容在网络上为数不多的综述性质的文章,针对预训练模型的有关内容也讲解的较为全面。然而实际上,在近年,尤其是2022年间,扩散模型在CTG上的应用其实是十分广泛的,而基于VAE的方法也层出不穷,由于这些内容并不是基于预训练的模型,综述内容并没有覆盖到这些,因此本文旨在整理有关的CTG的内容以及文章,尝试在整理这篇博客的过程当中寻找到各个文章之间的内容联系,划分出大致的文章类别,从合适的角度去俯瞰这些工作。
说了一把子废话,画了一些大饼,现在开始尝试整理。我仍然将Survey文章作为重要的参考文献和出发点。
基于预训练的CTG模型
正如很多文章所说的一样,预训练模型正在大放异彩,因此尝试在CTG的任务下将目光聚焦在预训练模型是很正常的。很多有关的技术博客都说明了,将已经在大规模语料预训练过的预训练模型应用在CTG任务当中是存在难度的,从大的方向上来说,目前我们主要有三种使用方法:
- 改良派:通过微调的方法,类似原先的方式,使用一些技巧在预训练的基础上继续Fine-tuning。
- 革命派:就是有钱!打破原先的预训练模型,另起炉灶,重新训练一个大规模的预训练模型。
- 保守派:摆烂,我就想用预训练模型,因此只在预训练的解码过程当中使用一些额外的方法和模型来控制生成的内容。
改良派
改良派实际上是沿用了预训练时代当中一个比较通用的范式,也就是Fine-Tuning范式,我们使用一部分特定的语料,将可控文本生成的任务当中的可控部分,寄托于我们所给出的特定的语料。
对于改良派,Survey当中也给出了大概三种分类:
- 基于adapter的方法:所谓adapter,其实就是在模型当中的某层添加少量的参数,我们冻结PLM的参数,将我们可控的希望寄托在adapter上。直观的感觉上来讲,对于多种其他的任务来说,我们也可以应用这种方法进行类似的处理,将其他任务的特性寄托在adapter上。
- 基于prompt的方法:基于prompt的方法实际上还是比较丰富的,简单的来说,我们在输入当中使用一定的token来对PLM当中添加额外的控制。与adapter相比,prompt的方法实际上是添加在输入上,而adapter实际上是添加在模型当中的。(顺便一提,与prefix-tuning相比,prompt的方法仍然是给定了prompt去微调PLM,而prefix-tuning则是完全微调trainable的添加在输入的前缀)
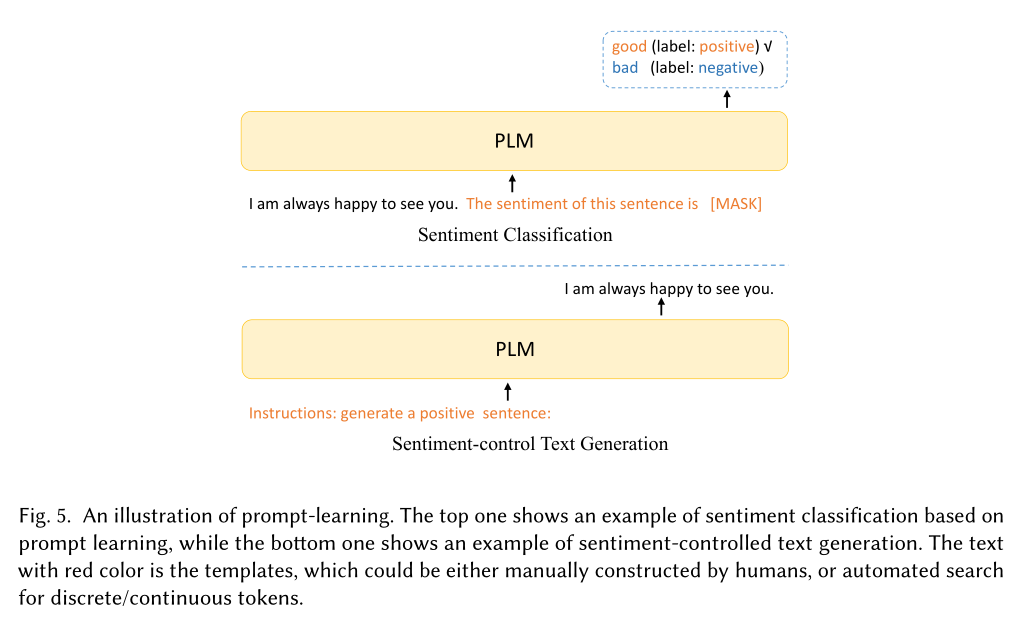
- 基于强化学习的方法:通过奖励机制来反馈控制条件的实现,有人使用强化学习的方法,引导GPT2朝着指定的条件方向(即目标类)生成文本内容,具体来说,就是在GPT2的softmax和argmax函数之间增加了一个额外的RL阶段,根据RL的奖励信号朝着目标标签更新,即通常来讲,这里是结合RL使用微调的方法。
Fine-Tuning
在这个类别下的是纯纯什么都没干的,好像看起来看起来就是在人家的框架上微调了一下。
Survey当中列举的任务主要是AMR-to-text(抽象语义到文本任务)。
| 文章名称 | 模型 | 目标任务 | 备注 |
|---|---|---|---|
| Text-to-Text Pre-Training for Data-to-Text Tasks | T5 | Data-to-Text | 仅仅实现了一个非结构文本的 转换,直接在T5的基础上微调 |
| DART: Open-Domain Structured Data Record to Text Generation | BART,T5 | Data-to-Text | 构造了一个新数据集DART, 合并了E2E和WebNLG, 还取了很多别的数据 |
| Investigating Pretrained Language Models for Graph-to-Text Generation | BART,T5 | Graph-to-Text | 调查并比较了BART和T5 这两个PLMs,用于图到文本生成 |
Adapter
在这个类别下的,通常是在原先的预训练模型的基础上添加了一些结构,并且在这些结构的基础上冻结原先大部分PLMs的参数,使用adapter来进行属性的控制。
| 文章名称 | 模型 | 目标任务 | 备注 |
|---|---|---|---|
| Technical Report: Auxiliary Tuning and its Application to Conditional Text Generation | 自回归的 Transformer | Data-to-Text | 提出了一种新的微调范式 Auxiliary Tuning,流畅性 更好 |
| Structural Adapters in Pretrained Language Models for AMR-to-text Generation | 自回归的 Transformer | Graph-to-Text | 提出了STRUCTADAPT,建 模图结构 |
| DIALOGPT : Large-Scale Generative Pre-training for Conversational Response Generation | GPT2 | Dialogue Generation | 构造了MMI评分函数,惩 罚乏味假设 |
Reinforcement Learning
强化学习在可控文本生成任务当中,其主要的方法是通过反馈控制条件是否或如何实现,从而作为对预训练模型微调的奖励,同时,一般为了保证生成文本的流畅性,还会在奖励函数当中添加一个惩罚项。
| 文章名称 | 模型 | 目标任务 | 备注 |
|---|---|---|---|
| Data Boost: Text Data Augmentation Through Reinforcement Learning Guided Conditional Generation | GPT2 | 分类任务(生成部 分作为数据增强) | 增加了额外的RL阶段,更新 PLM的隐层参数 |
| Learning to summarize from human feedback | GPT3 | 英文摘要 | 结合了人工评估,使用强 化学习的方法微调 |
| Controllable Neural Story Generation via Reinforcement Learning | LSTM | 可控故事生成 | 在所有时间步产生中间奖励, 反向传播到语言模型当中 |
革命派
正如我们前面所介绍的,改革派直接进行微调,或者借助adapter等结构来在已有的预训练模型的基础上进行微调,而革命派则直接改变原有的预训练模型的架构,或者干脆从头训练一个预训练模型,从而使其更加适配下游任务。这样的方法有望大幅提升文本生成的质量和可控性,但是存在标记数据不足和计算资源消耗大的局限性。
| 文章名称 | 模型 | 目标任务 | 备注 |
|---|---|---|---|
| CTRL: A CONDITIONAL TRANSFORMER LANGUAGE MODEL FOR CONTROLLABLE GENERATION | Transformer | 各种可控 生成任务 | 在文本语料库前添加了控 制代码,重新训练 |
| POINTER: Constrained Progressive Text Generation via Insertion-based Generative Pre-training | Transformer | 可控文本 生成 | 修改了transformer结构, 先产生约束词,再插入其他词 |
| Parallel Refinements for Lexically Constrained Text Generation with BART | BART | 可控文本 生成 | 修改了BART结构,引导模型 预测替换和插入的token位置 |
| CoCon: A Self-Supervised Approach for Controlled Text Generation | GPT | 可控文本 生成 | 将控制块放入GPT模型当中 |
保守派
直接采用后处理的方法,即我们仅仅在解码阶段应用一定的策略,使我们产生的语句可以获得想要的属性和内容。显而易见的是,这样的方法我们可以使用较小的计算资源来获得不错的结果,同时也最大限度的激活了预训练模型的潜力。
| 文章名称 | 模型 | 目标任务 | 备注 |
|---|---|---|---|
| Plug and Play Language Models: A Simple Approach to Controlled Text Generation | GPT2 | 各种可控 生成任务 | 使用一个属性判别器来 指导文本生成 |
| FUDGE: Controlled Text Generation With Future Discriminators | GPT2 | 各种可控 生成任务 | 将未来产生的token添 加到输出当中判断属性 |
非预训练的CTG模型
VAE & GAN
本部分内容,尤其是有关VAE以及GAN的内容主要参考于An Overview on Controllable Text Generation via Variational Auto-Encoders这篇文章,后文称作Overview。
Overview当中主要从训练的方法来对不同的应用于可控文本生成的自编码器模型进行了有关的分类,主要分为有监督的,半监督的以及无监督的方法。
监督的方法
对于将VAE应用于可控文本生成任务,最直观的做法就是我们将给出的所有标签都合并到生成过程当中。也因此我们引出了CVAE等模型结构。
| 文章名称 | 目标任务 | 备注 |
|---|---|---|
| Improve Diverse Text Generation by Self Labeling Conditional Variational Auto Encoder | 各种可控 生成任务 | 将x注入z,回避了潜在 的KL崩溃问题 |
| FUDGE: Controlled Text Generation With Future Discriminators | 各种可控 生成任务 | 将未来产生的token添 加到输出当中判断属性 |
半监督的方法
无监督的方法
评价指标的分类
Diffusion Model
总结
常见的生成任务和数据集
| 生成任务 | 数据集 | 备注 |
|---|---|---|
| Data-to-Text | ToTTo | 自然语言描述的维基百科单元格 |
| MultiWoz | 包含10K个人际对话的语料库,用于开发面向任务的对话系统 | |
| Cleaned E2E | 对话行为含义表示(MR)和餐厅领域的自然语言引用到文本描述 | |
| DART | <三元组,句子>到文本描述 | |
| 被抓取的Reddit自2005年至2017年的评论链 | ||
| Graph-to-Text | WebNLG | 主题-对象-谓词三元组的图和文本描述 |
| AMR | 谁对谁做什么”的有根有向图 | |
| AGENDA | 论文标题,一个KG,以及相应的摘要 | |
| 英文摘要 | TL;DR | 300万篇不同主题的帖子 |
| 故事生成 | CMU movie summary corpus | 电影故事语料库,种类很多 |
| 1 | 2 | 3 |
| 2 | 3 | |
| 2 | 3 | |
| 1 | 2 | 3 |